Solemn Declaration: The dataset analyzed in this article is for learning and communication purposes only. This article does not provide any download links and has been deleted within 24 hours. Please do not use it for illegal purposes; otherwise, you will bear all consequences.
tb#
Cause of the Matter#
To-do item - Organizing the fixed character separated txt files of pants into MySQL.
The txt is separated by four dashes ---- to divide the email and password (please ignore my magical obfuscation technique):
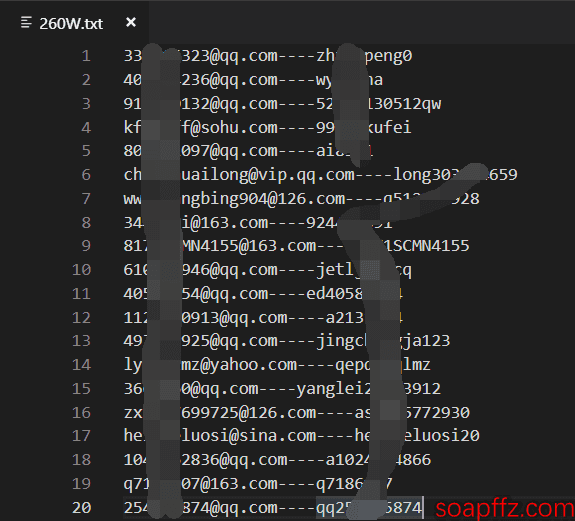
This article will try to use Python to batch import these fixed character separated txt files into the local mysql database.
Some Process Explanations Below#
About File Encoding and Line Terminators#
File Encoding#
Of course, it's best if all tools and files are in UTF-8 encoding!
However, just like the four texts I mentioned earlier, they are downloaded as:
ASCII text, with CRLF line terminators
What does it look like when manually modified to UTF-8?
UTF-8 Unicode (with BOM) text, with CRLF line terminators
These two types are the most commonly seen. Ah? You ask me why I can use Linux commands on win, because I accidentally discovered that git for windows provides many Linux commands. When you download Virtualbox, it will prompt you to install it. You can also directly download it: Portal
I recommend those who haven't installed it to do so; it's very useful (if these two companies see this, please pay me advertising fees, thank you). We will also use iconv, sed, and other Linux commands later.
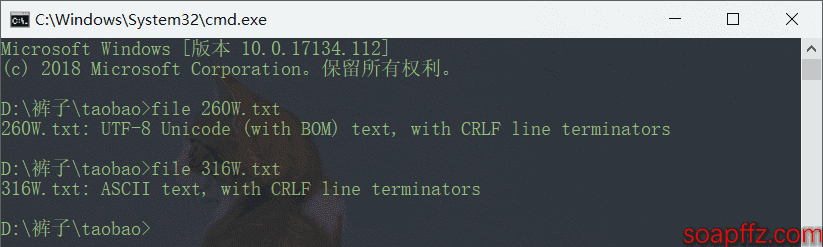
You can check the file encoding and line terminators using the command file xxx.txt.
If we import txt with ANSI encoding into a utf-8 encoded database, it will throw an error:

1300, "Invalid utf8 character string: '˹'"
I will convert all files to UTF8 encoding. First, let's use the previously mentioned command line file command to test this, which will yield results instantly.
We have also introduced the execution of command line statements in Python in the previous article "Python3 Prints All Wi-Fi Accounts and Passwords on the Computer." Here, we will directly present the code:
import os
txt_name_list = ['260W.txt', '316W.txt', '440W.txt', '445W.txt',]
for i in txt_name_list:
print(os.popen('file {}'.format(i)).read())
The result is as follows:
It shows that the first one is UTF-8, while the others are ANSI, but in fact, 316W.txt is also UTF-8, indicating that the accuracy of the file command is not high.
Let's try the chardet library in Python3, referring to the article: Detecting and Converting Text File Encoding in Python
for i in txt_name_list:
detector = UniversalDetector()
print("Detecting the file encoding of {}".format(i))
detector.reset()
for line in open(i, 'rb').readlines():
detector.feed(line)
if detector.done:
break
detector.close()
print(detector.result)
Detecting large files is indeed very slow, but after waiting a long time, it can still detect that 316W.txt is UTF-8 encoded.
Let's modify it by adding the parameter 1000000 in readlines(), and we find that it cannot detect:
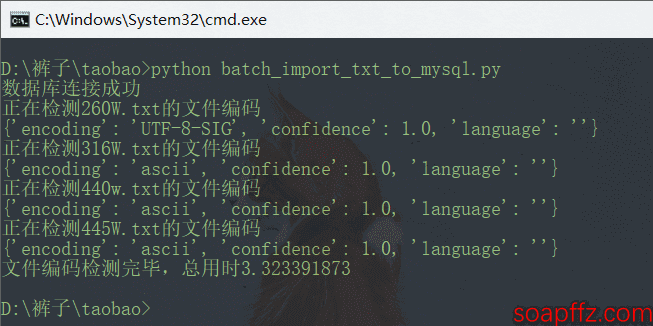
When we increase it to 2000000 lines, it can detect again:
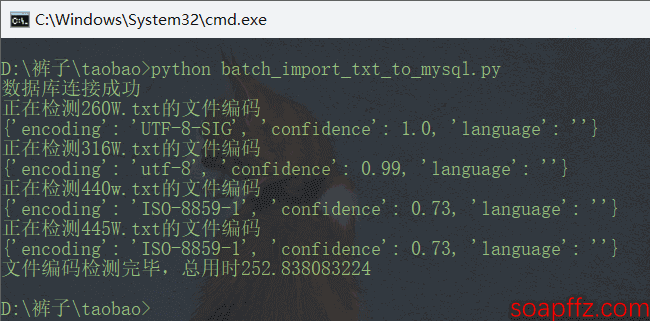
So let's lazily set 200W as the maximum detection limit.
After obtaining the file encoding, we check whether it is utf8. If not, we will use the command iconv to convert the file encoding and rename it:
src_enc = detector.result['encoding']
# If the encoding is not utf-8, use iconv to convert xx.txt to utf8-xx.txt
if 'utf-8' not in src_enc.lower():
utf8_txt_name = "utf8-{}".format(i)
print("{} is not utf-8 encoded, converting to {}".format(i, utf8_txt_name))
try:
os.popen(
'iconv -c -f {} -t utf-8 {} > {}'.format(src_enc, i, utf8_txt_name))
except Exception as e:
print("Conversion error: {} \n Exiting program!".format(e))
exit(0)
processed_txt_filename_list.append(utf8_txt_name)
else:
processed_txt_filename_list.append(i)
Line Terminators#
CRLF represents Carriage Return and Line Feed, where CR is Carriage Return and LF is Line Feed. Generally, CRLF is the default. CRLF represents \n\r, which is the default line break method for Windows; LF represents \r, which is the default line break method for Unix systems.
Files from the Unix system will appear as a single line when opened in Windows (they can also be displayed normally when opened in VSCODE; if VSC sees this, please pay me). Conversely, files from Windows may have an extra
^Msymbol at the end of each line when opened in Unix.
I won't change it; I will use CRLF for everything. If you want to change it, you can also use the sed command to replace all possible \n\r with \n.
sed ’s/^M//’ filename > tmp_filename
For other methods, refer to the article: Removing \r from Files in Linux
Basic Operations of pymysql#
The basic usage of connecting to the database and executing sql statements using pymysql is as follows:
# Connect to the database; the password can be followed by the database name
connect_mysql = pymysql.connect('localhost', 'root', 'root', charset='utf8')
# Get a cursor object that can execute SQL statements; the results returned are displayed as tuples by default
cursor = connect_mysql.cursor()
# Execute SQL statement
cursor.execute('select * from `users`;')
# Close the database connection
connect_mysql.close()
However! When I used the pymysql.connect() function to connect to the database and executed the subsequent load file import command load data local infile xxx.txt, I found that it threw an error:
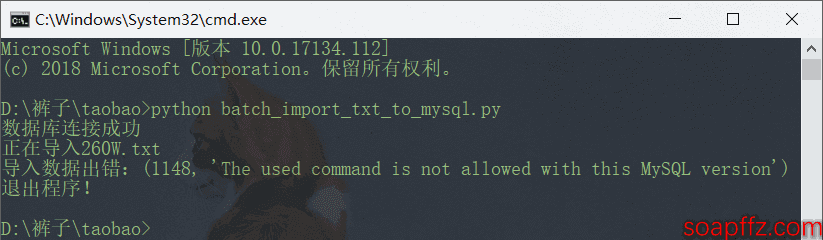
1148, 'The used command is not allowed with this MySQL version'
After searching online, I found that
For security reasons, loading data from the client host via the load data command is not allowed by default.
I found a solution in this article:
connect_mysql = pymysql.connections.Connection('localhost', 'root', 'root', charset='utf8', local_infile=True)
The Full Code is as Follows:#
The comments should be understandable; if you have any questions, feel free to leave a message for discussion~::quyin:1huaji::
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: Batch import fixed character separated txt to MySQL
@time: 19-04-06
'''
import os # Get text names and execute cmd commands
import pymysql # Use pymysql for Python3, mysqldb for Python2
from chardet.universaldetector import UniversalDetector # Determine file encoding
import timeit # Calculate time taken
def create_db():
# Create the database if it does not exist, with character set utf8 and collation utf8_general_ci
sql_create_db = "CREATE DATABASE IF NOT EXISTS `soendb` default charset utf8 COLLATE utf8_general_ci;"
# Create the taobao table with two fields: mail and passwd
sql_create_table = """
CREATE TABLE IF NOT EXISTS `taobao` (
`mail` varchar(255) DEFAULT NULL,
`passwd` varchar(255) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
"""
# Choose what you need to create
try:
cursor.execute(sql_create_db)
cursor.execute('use soendb;') # Set the current database to the one just created
cursor.execute(sql_create_table)
except Exception as e: # Catch all exceptions and print; python2 is Exception, e
print("Database creation error: {}\nExiting program!".format(e))
connect_mysql.rollback() # Rollback on error
connect_mysql.close() # Close the database connection
exit(0)
def textencoding_lineterminators_modifi(txt_name_list):
# Process text encoding and characters
processed_txt_filename_list = []
for i in txt_name_list:
detector = UniversalDetector()
print("Detecting the file encoding of {}".format(i))
detector.reset() # Clear the feeding pool
for line in open(i, 'rb').readlines(20000000): # Iterate 200W lines, enough to detect results
detector.feed(line) # Feed
if detector.done: # Exit if there is a result
break
detector.close()
src_enc = detector.result['encoding']
# If the encoding is not utf-8, use iconv to convert xx.txt to utf8-xx.txt
if 'utf-8' not in src_enc.lower():
utf8_txt_name = "utf8-{}".format(i)
print("{} is not utf-8 encoded, converting to {}".format(i, utf8_txt_name))
try:
os.popen(
'iconv -c -f {} -t utf-8 {} > {}'.format(src_enc, i, utf8_txt_name))
except Exception as e:
print("Conversion error: {} \n Exiting program!".format(e))
exit(0)
processed_txt_filename_list.append(utf8_txt_name)
else:
processed_txt_filename_list.append(i)
return processed_txt_filename_list
def import_txt_to_mysql(txt_name):
# Import txt to mysql
sql_insert_txt = """
LOAD DATA LOCAL INFILE "{}" INTO TABLE `taobao`
FIELDS TERMINATED BY '----' LINES TERMINATED BY '\r\n';
""".format(txt_name)
# --Fields are separated by '----' (example), records are separated by CRLF (example)
try:
cursor.execute('use soendb;')
cursor.execute(sql_insert_txt)
# Commit to the database for execution
connect_mysql.commit()
except Exception as e:
print("Data import error: {}\nExiting program!".format(e))
connect_mysql.rollback()
connect_mysql.close()
exit(0)
if __name__ == "__main__":
start_time = timeit.default_timer()
# Connect to the database; the password can be followed by the database name
try:
connect_mysql = pymysql.connections.Connection(
'localhost', 'root', 'root', charset='utf8', local_infile=True)
# Get a cursor object that can execute SQL statements; the results returned are displayed as tuples by default
cursor = connect_mysql.cursor()
except Exception as e:
print("Database connection error: {}\nExiting program!".format(e))
exit(0)
print("Database connection successful")
create_db() # Optional, create database and table
# Get the names of all txt files in the current directory
src_txt_filename_list = [filename for filename in os.listdir(
".") if filename.split(".")[-1] == 'txt']
if src_txt_filename_list: # If the current directory txt name list is not empty, use the list to detect encoding to get the new txt name list
processed_txt_filename_list = textencoding_lineterminators_modifi(
src_txt_filename_list)
for txt_name in processed_txt_filename_list:
try:
print("Importing {}".format(txt_name))
import_txt_to_mysql(txt_name)
except Exception as e:
print("Data import error: {}\nExiting program!".format(e))
connect_mysql.rollback()
connect_mysql.close()
exit(0)
else:
print("No txt file names obtained, please check again!")
end_time = timeit.default_timer()
print("Database import completed, total time taken {}".format(end_time - start_time))
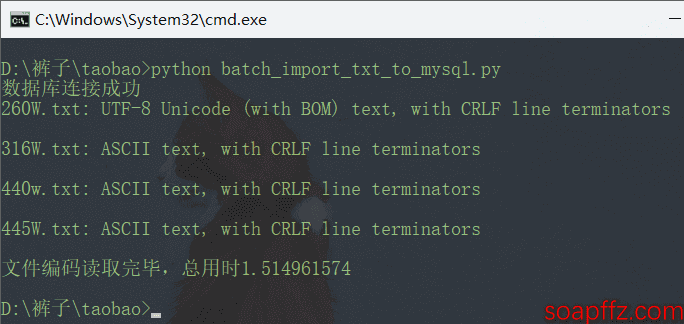
The result is as follows:
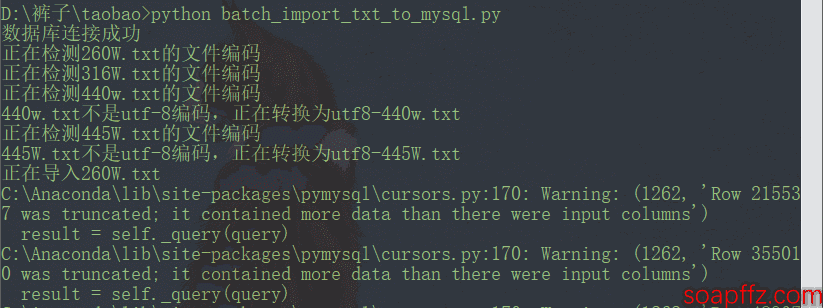
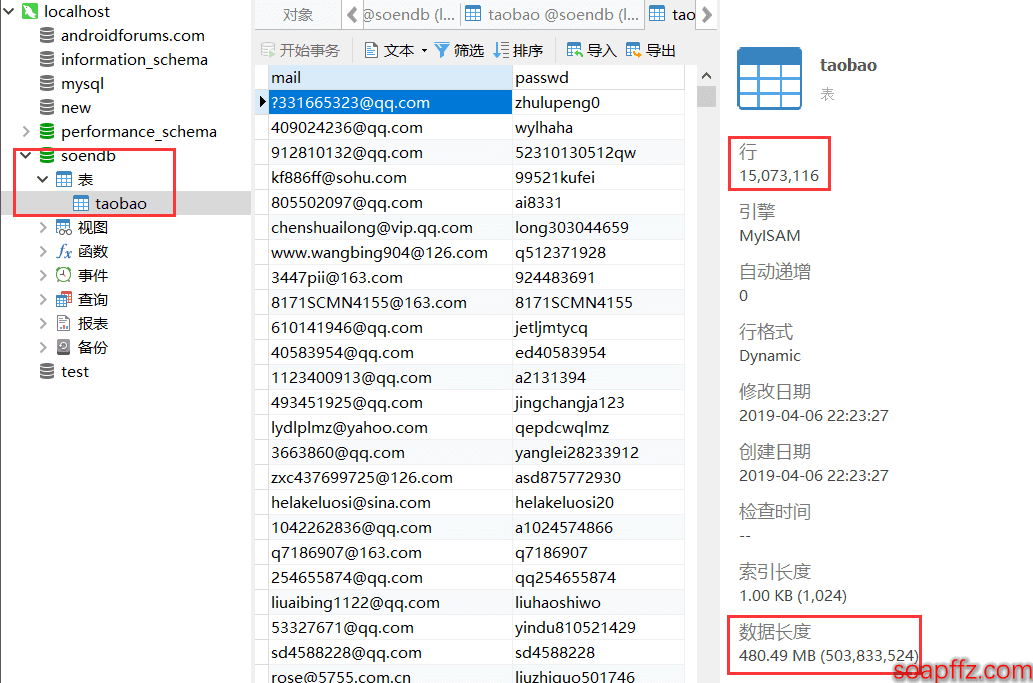
In fact, over 200 seconds, more than 99% of the time is spent verifying the file encoding. However, as I mentioned in the article, the accuracy of the file command is basically only applicable to files with a 100% credible encoding detected by chardet. The rest are mostly inaccurate, but chardet is too slow, even though I have set a 200W line limit as a workaround.
Of course, you can also skip verification and convert all files to utf-8 encoding.
So, if anyone has good tools for batch verification and modification of file encoding under Windows (or even better, if they can be found under Linux), please feel free to leave comments for discussion!
Notes:
- The path for loading files must be
/, but the default copy in win is\. This article does not handle this because this py file is executed in the directory where the txt files are located, so there is no path issue. - For operations like insert, update, delete, etc., you need to use
connect_mysql.commit()to commit to the database for execution. For operations like querying, creating databases, and tables, this statement is not needed. - Most of the code is repetitive, but for easier reading and to prevent some readers from not needing certain functions, I still wrote them separately.
Reference Links:
- Detecting and Converting Text File Encoding in Python
- Removing \r from Files in Linux
- Python3 MySQL Database Connection - PyMySQL Driver
- Basic Usage of PyMySQL
- PyMYSQL Module
BreachCompilation#
[Updated 19-4-10] Checking the encoding of each file is really too laborious. While organizing the 1.4 billion leaked data from the security pulse article and the data security consulting articles published by Freebuf and other websites 1.4 billion email leaked password plaintext information query website suddenly appears on the internet, the data here is like this:
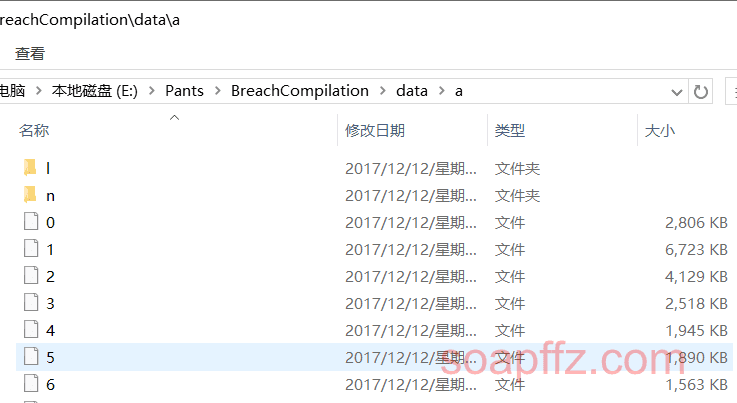
Many folders have subfolders, and the data files have no suffix. We mainly use the command cat * > 1.txt to merge them into the specified folder.
When I was about to finish writing the code, I found that a single shell command could merge all files in the folder (including subfolders) reference article:
> find . Recursively search for files starting from this folder
> -type f Specify the file type as a regular file; other options include: d directory, l symbolic link, c character device, b block device, s socket, etc.
> -amin/-mmin/-cmin Can specify the access time/modification time/change time of the file. e.g. find . -type f -atime +7 -print prints all files accessed more than seven days ago.
> -perm Find files based on file permissions
> -user Find files based on file owner
> -delete Delete the found files
> -exec Execute commands on the found files, formatted as: -exec ./commands.sh {} \;
At that moment, I was in despair::quyin:hematemesis::. Fortunately, I tried the win built-in find command, which can only search for strings within files, and the installed Git, even if I selected the option to use Unix to override some of the built-in win commands, still cannot use find, so my mood returned to normal::quyin:witty::
The main core command for text organization: Enter each folder and execute the cat command, with each command not blocking, but hoping for multithreading without interference.
Reference article: Various Implementations and Pros and Cons of Executing cmd in Python (subprocess.Popen, os.system, and commands.getstatusoutput)
And I will add to this article:
The os.system() function is blocking but does not return error messages; each command must complete before the next one executes.
In version 3.x, the getstatus() method of the commands library was removed, and getoutput() and getstatusoutput() were moved to the subprocess module. (i.e., the commands library is no longer used in version 3.x, but the subprocess library is used instead.)
Here is the full code:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: Batch import fixed character separated txt to MySQL (Rough Encoding Conversion)
@time: 19-04-11
'''
import os # Get text names and execute cmd commands
import shutil # File and directory related processing
import subprocess # Execute cmd commands
import pymysql # Use pymysql for Python3, mysqldb for Python2
import timeit # Calculate time taken
import re # Use regular expressions to find and separate file names
class db_progress:
def __init__(self):
self.collections_dir = 'E:\Pants\BreachCompilation\collections'
self.connect_mysql()
self.create_db()
def connect_mysql(self):
# Connect to the database; the password can be followed by the database name
try:
self.mysql_conn = pymysql.connections.Connection(
'localhost', 'root', 'root', charset='utf8', local_infile=True)
# Get a cursor object that can execute SQL statements; the results returned are displayed as tuples by default
self.cursor = self.mysql_conn.cursor()
print("Database connection successful")
except Exception as e:
print("Database connection error: {}\nExiting program!".format(e))
exit(0)
def create_db(self):
# Create the database if it does not exist, with character set utf8 and collation utf8_general_ci
sql_create_db = "CREATE DATABASE IF NOT EXISTS `14yi` default charset utf8 COLLATE utf8_general_ci;"
# Choose what you need to create
try:
self.cursor.execute(sql_create_db)
self.cursor.execute('use 14yi;') # Set the current database to the one just created
except Exception as e: # Catch all exceptions and print; python2 is Exception, e
print("Database creation error: {}\nExiting program!".format(e))
self.mysql_conn.rollback() # Rollback on error
self.mysql_conn.close() # Close the database connection
exit(0)
def import_txt_to_mysql(self, txt_name_list):
if not txt_name_list:
# If txt_name_list is not obtained, it indicates that file encoding processing failed
print("File encoding may be incorrect, no txt name list obtained, please check again!\nExiting program!")
print(0)
else:
# Change the current working directory to the collections folder
os.chdir(self.collections_dir)
# Import txt to mysql
for txt_name in txt_name_list:
table_name = re.findall(".*data-(.*).txt", txt_name)[0]
# Create a table with three fields: email, passwd, and username
sql_create_table = """
CREATE TABLE IF NOT EXISTS `{}` (
`mail` varchar(255) DEFAULT NULL,
`passwd` varchar(255) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
""".format(table_name)
# Insert the file into the database
sql_insert_txt = """
LOAD DATA LOCAL INFILE "{}" INTO TABLE `{}`
FIELDS TERMINATED BY ':' LINES TERMINATED BY '\n';
""".format(txt_name, table_name)
# --Fields are separated by ':' (example), records are separated by LFCR (example)
try:
print("Importing {}".format(txt_name))
self.cursor.execute('use 14yi;')
self.cursor.execute(sql_create_table)
self.cursor.execute(sql_insert_txt)
self.mysql_conn.commit() # Commit to the database for execution
except Exception as e:
print("Data import error: {}\nExiting program!".format(e))
self.mysql_conn.rollback()
self.mysql_conn.close()
exit(0)
class txt_progress:
def __init__(self):
self.root_dir = 'data'
self.collections_dir = 'E:\Pants\BreachCompilation\collections'
self.utf8_txt_name_list = []
if os.path.exists(self.collections_dir):
# If the directory exists, delete it along with subfolders
shutil.rmtree(self.collections_dir)
os.mkdir(self.collections_dir)
self.txt_collections(self.root_dir)
self.txt_coding_conv()
def txt_collections(self, path):
# Merge files in each folder into the collections_dir folder
for item in os.listdir(path):
subFile = os.path.join(path + "\\" + item)
if os.path.isdir(subFile):
try:
# Use regular expressions to find and separate file names
txt_name = os.path.join(self.collections_dir, re.split(
r'BreachCompilation\\', os.path.abspath(subFile))[-1].replace("\\", '-'))
print("Converting {}".format(txt_name))
# Enter each folder and merge all content into the corresponding txt in collections
cc = 'cd {} && cat * > {}.txt'.format(
os.path.abspath(subFile), txt_name)
subprocess.run(cc, shell=True, stdout=subprocess.PIPE)
except Exception as e:
print("Conversion error: {} \n Exiting program!".format(e))
exit(0)
self.txt_collections(subFile)
def txt_coding_conv(self):
os.chdir(self.collections_dir)
# Convert all files in the collections_dir folder to utf-8 encoding and return txt_name_list for insert_txt_to_mysql function
for item in os.listdir("."):
try:
utf8_txt_name = "utf8{}".format(item) # New name
# Force convert all txt to utf-8 encoding
subprocess.run('iconv -c -f ISO-8859-1 -t utf-8 {} > {}'.format(
item, utf8_txt_name), shell=True, stdout=subprocess.PIPE)
self.utf8_txt_name_list.append(utf8_txt_name)
except Exception as e:
print("Conversion error: {} \n Exiting program!".format(e))
exit(0)
return self.utf8_txt_name_list
if __name__ == "__main__":
start_time = timeit.default_timer()
progress_db = db_progress()
progress_txt = txt_progress()
# Pass the converted utf8-_txt_name_list to the import database function
progress_db.import_txt_to_mysql(progress_txt.utf8_txt_name_list)
end_time = timeit.default_timer()
print("Program execution completed, total time taken {}".format(end_time - start_time))
The result is as follows:
Currently, there is no effect, and there are still some small issues.
7x7x#
[Updated 19-04-13] With the template, the problem of importing other fixed character separated txt files into MySQL is very simple; just modify the template.
This time it is the database of a domestic game website 7x7x (collected from the internet):
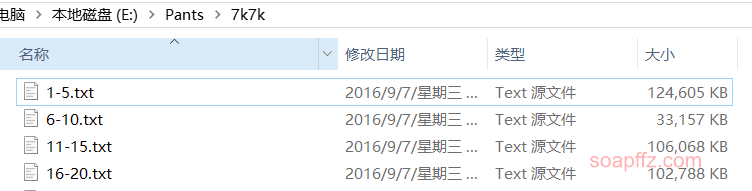
Using \t as the separator, the special feature of this database is that it contains both email\tpassword and username\tpassword data:
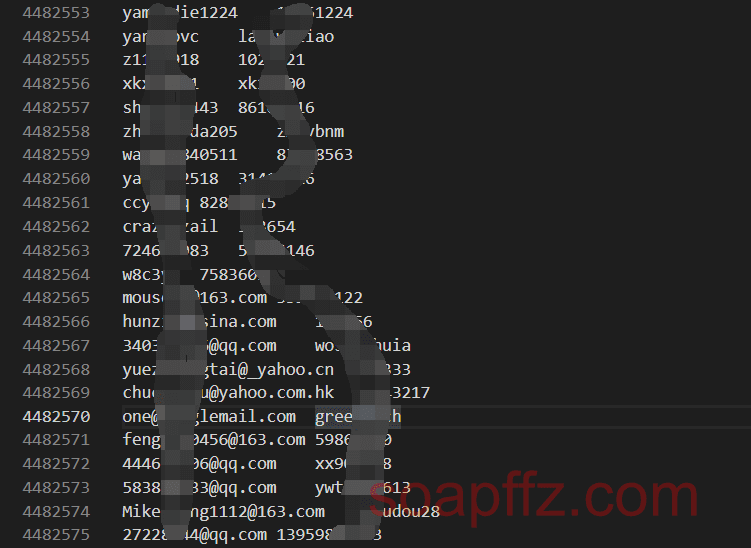
Therefore, when creating the table, we need to create three fields: email, passwd, and username.
When detecting that a line does not contain the @ symbol (i.e., does not contain an email), it will be rearranged as \tpassword\tusername (because the data of email-passwd accounts accounts for a large proportion, so username is placed last).
The full code is as follows:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: Batch import fixed character separated txt from 7k7k database to MySQL (Encoding Conversion)
@Comment: The texts from 7k7k are detected as utf-8 using text encoding detection methods, so no encoding conversion is added in this program.
@comment: However, since there are both email-password and username-password, a text organization function is added.
@time: 19-04-13
'''
import os # Get text names and execute cmd commands
import subprocess
import pymysql # Use pymysql for Python3, mysqldb for Python2
import timeit # Calculate time taken
import re # Use regular expressions to find and separate file names
class db_progress(object):
def __init__(self):
self.connect_mysql()
self.create_db()
def connect_mysql(self):
# Connect to the database; the password can be followed by the database name
try:
self.mysql_conn = pymysql.connections.Connection(
'localhost', 'root', 'root', charset='utf8', local_infile=True)
# Get a cursor object that can execute SQL statements; the results returned are displayed as tuples by default
self.cursor = self.mysql_conn.cursor()
print("Database connection successful")
except Exception as e:
print("Database connection error: {}\nExiting program!".format(e))
exit(0)
def create_db(self):
# Create the database if it does not exist, with character set utf8 and collation utf8_general_ci
sql_create_db = "CREATE DATABASE IF NOT EXISTS `soendb` default charset utf8 COLLATE utf8_general_ci;"
# Check if the table exists; if it does, delete it and then create it
sql_table_detection = "DROP TABLE IF EXISTS `7k7k`;"
sql_create_table = """
CREATE TABLE `7k7k` (
`email` varchar(255) DEFAULT NULL,
`passwd` varchar(255) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
"""
try:
self.cursor.execute(sql_create_db)
self.cursor.execute('use soendb;') # Set the current database to the one just created
self.cursor.execute(sql_table_detection) # Check if the table exists; if it does, delete it and then create it
self.cursor.execute(sql_create_table)
except Exception as e: # Catch all exceptions and print; python2 is Exception, e
print("Database creation error: {}\nExiting program!".format(e))
self.mysql_conn.rollback() # Rollback on error
self.mysql_conn.close() # Close the database connection
exit(0)
def import_txt_to_mysql(self, txt_name_list):
if not txt_name_list:
# If txt_name_list is not obtained, it indicates that file encoding processing failed
print("File encoding may be incorrect, no txt name list obtained, please check again!\nExiting program!")
exit(0)
else:
# Import txt to mysql
for txt_name in txt_name_list:
sql_insert_txt = """
LOAD DATA LOCAL INFILE "{}" IGNORE INTO TABLE `7k7k`
FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\r\n';
""".format(txt_name)
# --Fields are separated by '\t' (example), records are separated by LFCR (example)
try:
print("Importing {}".format(txt_name))
self.cursor.execute('use soendb;')
self.cursor.execute(sql_insert_txt)
self.mysql_conn.commit() # Commit to the database for execution
except Exception as e:
print("Data import error: {}\nExiting program!".format(e))
self.mysql_conn.rollback()
self.mysql_conn.close()
exit(0)
class txt_progress:
def __init__(self):
self.processed_txt_filename_list = []
self.txt_process()
def txt_process(self):
# Organize texts containing both email-password and username-password
# Filter out special characters
special_characters = ['?', 'ú', 'ü']
for i in os.listdir("."):
if os.path.splitext(i)[1] == ".txt":
print("Organizing {}".format(i))
with open(i, 'r', encoding='utf-8') as f:
processed_txt_name = "processed-{}".format(i)
with open(processed_txt_name, 'a', encoding='utf-8') as k:
for j in f.readlines():
# Delete lines containing special characters
if any(chs in j for chs in special_characters):
continue
split = j.split('\t')
# If the account or password does not exist, delete this line
if '' in split:
continue
# If the password contains Chinese characters, delete this line
if re.compile(u'[\u4e00-\u9fa5]').search(split[-1]):
continue
# If the username is not an email, rearrange as: \tpassword\tusername\n
if '@' not in split[0]:
j = '\t' + \
split[-1].strip('\n') + \
'\t' + split[0] + '\n'
k.write(j)
self.processed_txt_filename_list.append(processed_txt_name)
return self.processed_txt_filename_list
if __name__ == "__main__":
start_time = timeit.default_timer()
progress_db = db_progress()
progress_txt = txt_progress()
progress_db.import_txt_to_mysql(progress_txt.processed_txt_filename_list)
end_time = timeit.default_timer()
print("Program execution completed, total time taken {}".format(end_time - start_time))
The running effect is as follows:
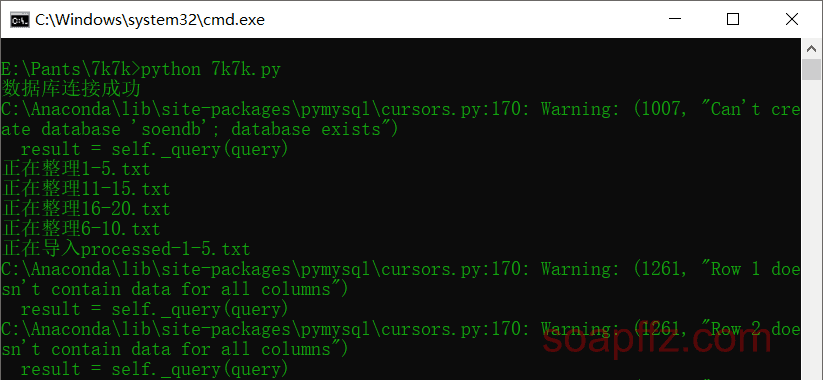
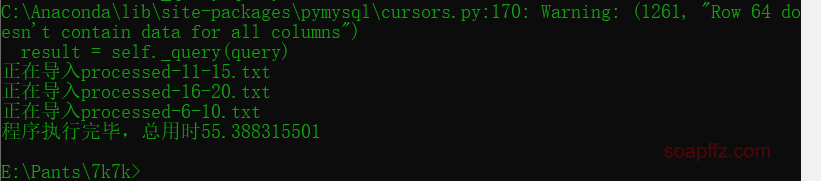
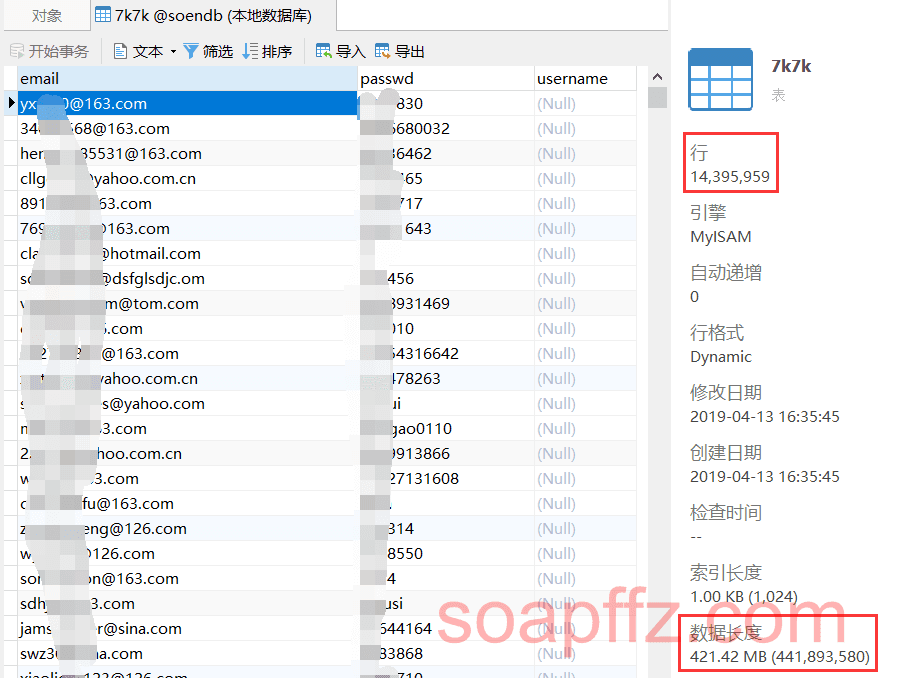
Solemn Declaration: The dataset analyzed in this article is for learning and communication purposes only. This article does not provide any download links and has been deleted within 24 hours. Please do not use it for illegal purposes; otherwise, you will bear all consequences.