Updated in the early morning of December 8, 2021
Added two lines of code
- Added initial string processing, directly removing those without a dot
., because both domain names and IPs must contain a dot, significantly reducing the frequency of special string reports. - Processed general wildcards like
*.10bis.co.il, directly removing the preceding*.while keeping other formats like*aaa.comoraaa.*unchanged.
The code has been directly updated in the code block below.
Yes, it's been almost a year without updates, finally here to write a post.
Significance of the Script's Birth#
As we all know, scripts, especially Python or Go scripts, are quite suitable for handling some simple information.
When digging into SRC, it is often encountered that some vendors directly throw a large chunk of text or simply provide an Excel file, stating this is the testing scope (non-scope content).
Moreover, it often contains Chinese characters, Chinese punctuation, IPs, and disorganized content.
So I wrote a script to handle this type of asset and organize the output.
The input txt can contain Chinese characters, Chinese punctuation, domain names, IPs, and any random characters.
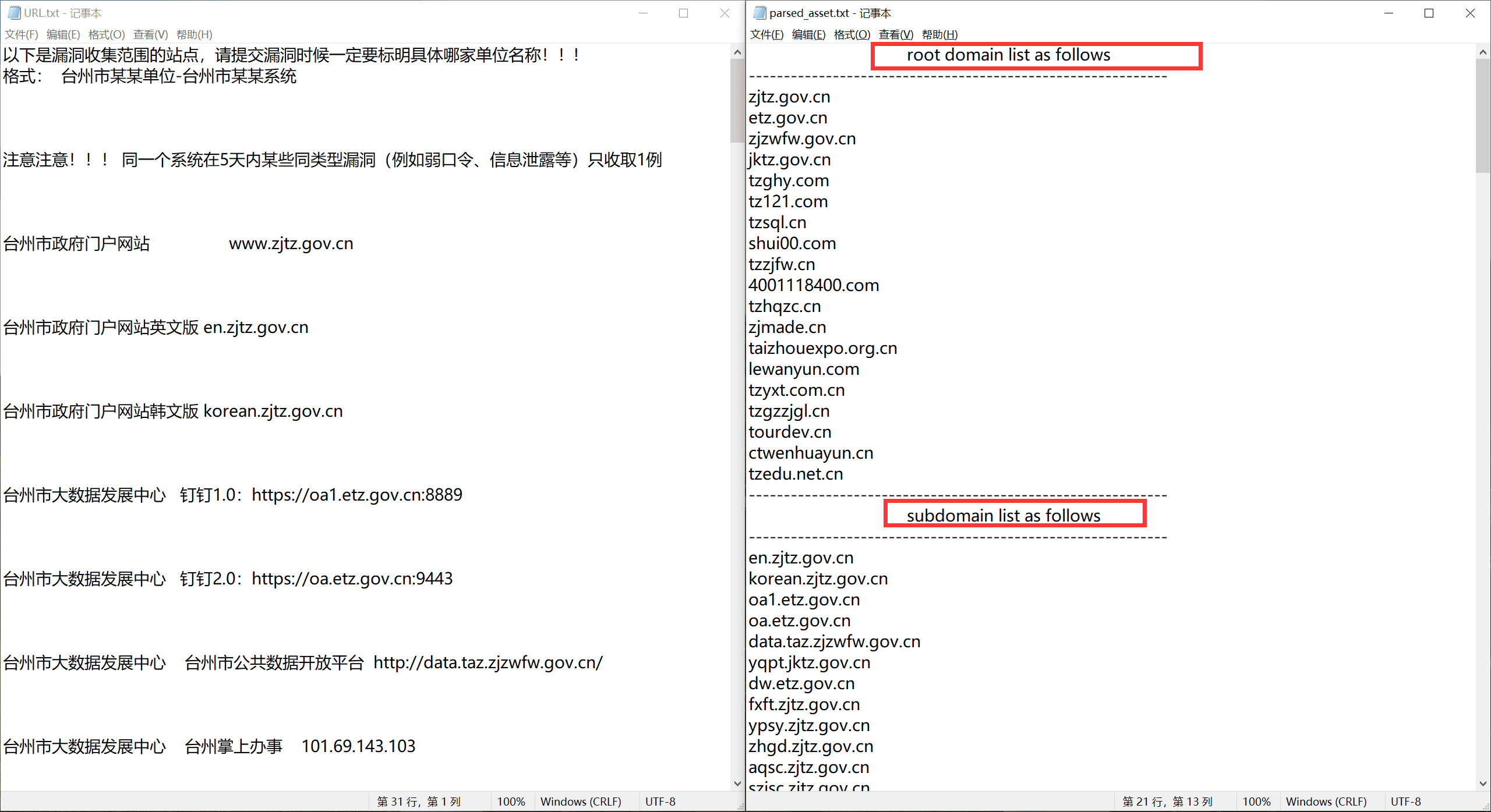
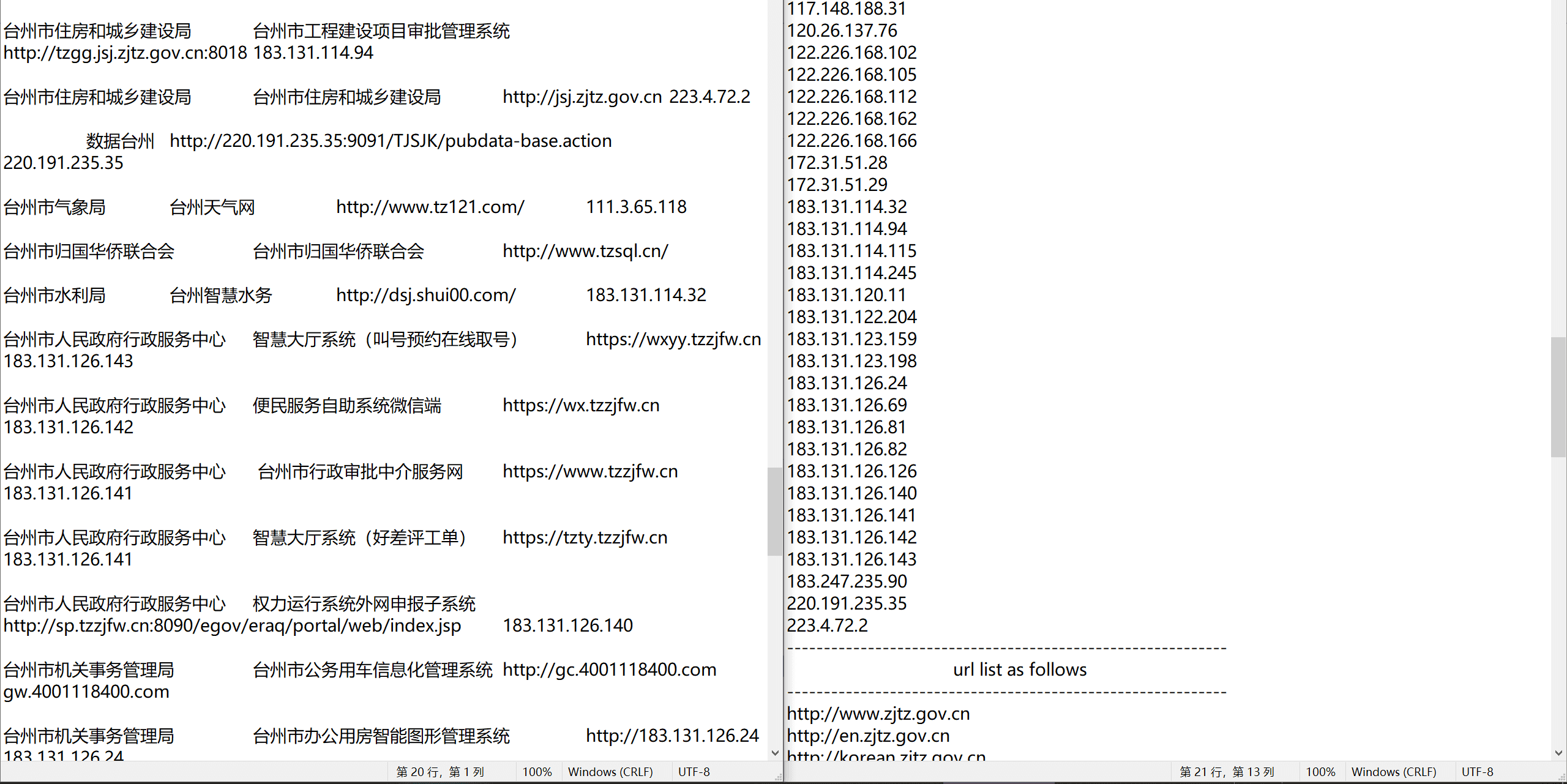
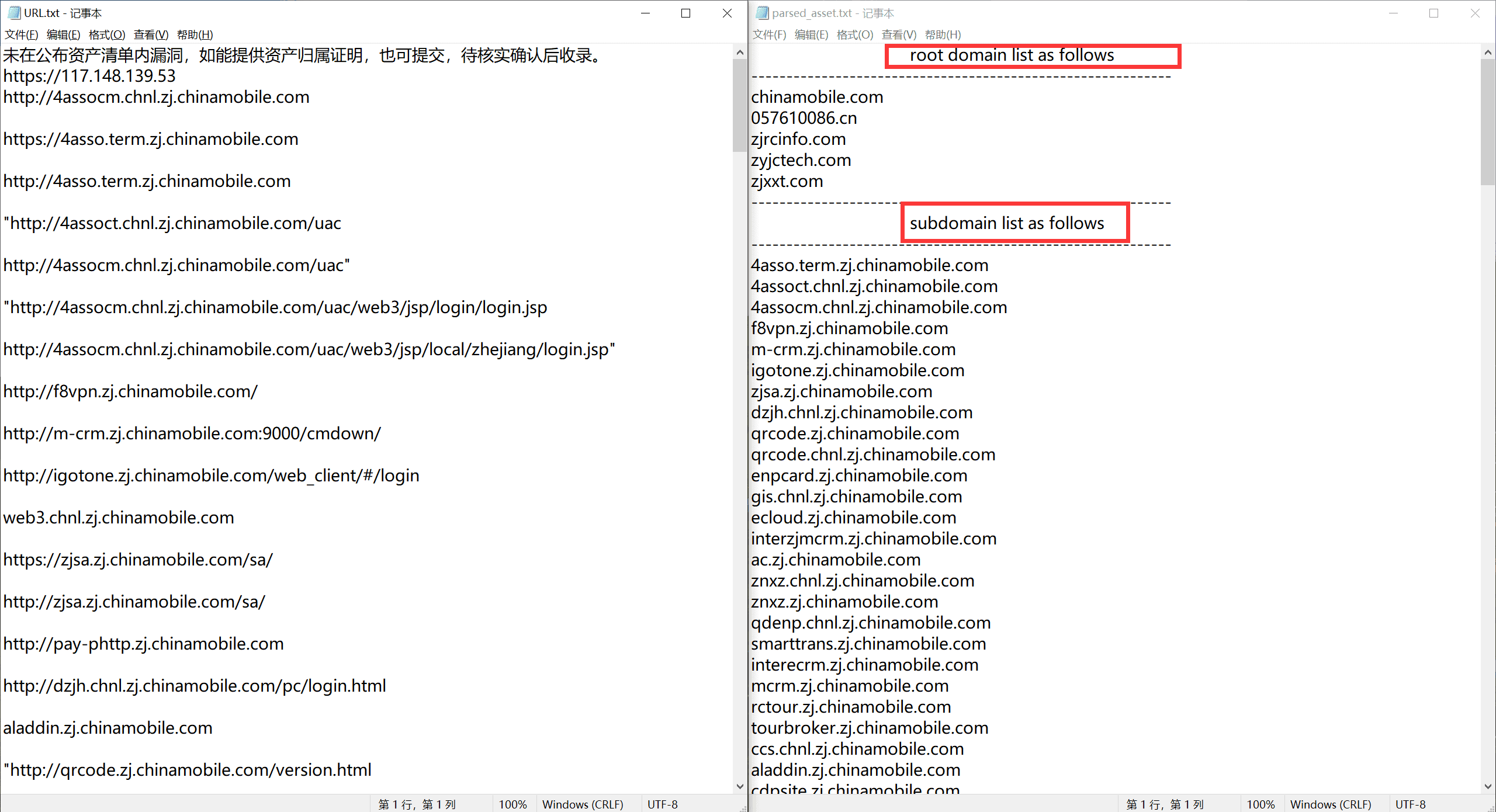
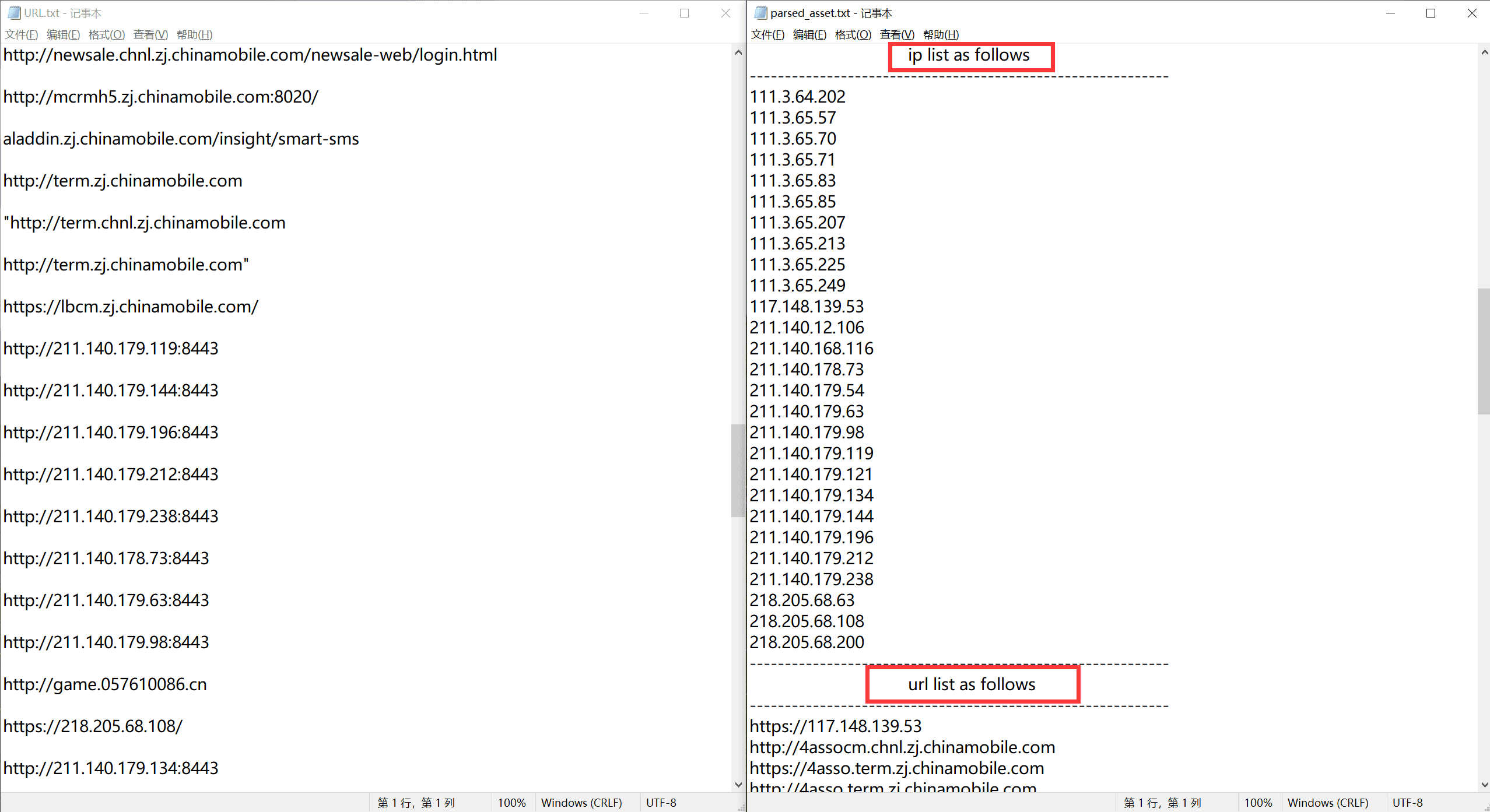
The output txt sequentially includes root domains, subdomains, IP addresses (sorted), and URL links.
Without further ado, here’s the script.
Script#
#!/usr/bin/env python
# Asset information organization, the original format can include IPs, URLs, http links with Chinese and Chinese punctuation, or a single IP or subdomain.
# After extraction, it includes pure domain names, a collection of root domains, a total of URLs, and pure IPs.
import tldextract
import re
import sys
from urllib.parse import urlparse
from zhon.hanzi import punctuation
import socket
import os
if len(sys.argv) != 2:
print("File not specified yet!")
exit(0)
subdomain_list, root_domain_list, ip_list, url_list = [], [], [], []
# Read the original file content, removing empty lines.
origin_file_content = re.sub(
r"\n[\s| ]*\n", '', open(str(sys.argv[1]), "r", encoding="utf-8").read())
# Remove Chinese characters.
content_without_chs = re.sub('[\u4e00-\u9fa5]', '', origin_file_content)
# Remove Chinese punctuation.
content_without_chs_punctuation = re.sub(
'[{}]'.format(punctuation), "", content_without_chs)
# Format into a single line, removing extra spaces at the beginning and end.
line_list = re.sub("http", " http", content_without_chs_punctuation).split()
# Remove lines that do not contain a dot, because regardless of the format, there must be a dot in the line.
line_list = [line.strip() for line in line_list if "." in line]
# If the file is too large, report an error and exit the program.
if len(line_list) > 100000:
print("The current text parsing count is too large, it is not recommended to use this script, it may hang, it is recommended to use this script in batches.")
print("Of course, if you want to write a text splitting script now, that's fine too.")
exit(0)
# for line in line_list:
# print(line)
# exit(0)
def domain_extract(string):
# Function to extract domain from URL, passing in URL or pure domain.
if bool(re.search(r"[a-zA-Z]", string)) and "." in string:
# Filter out strings without letters and those without a dot.
if "http" in string:
# URL processing method.
domain = urlparse(string).netloc.strip()
if len(domain) and bool(re.search(r"[a-zA-Z]", domain)):
if ":" in domain:
# Remove the port from the incoming URL that contains a port.
domain = domain.split(":")[0]
domain_processing(domain.strip().replace("www.", ""))
else:
# Pure domain processing method.
if ":" in string:
# Remove the port from the incoming URL that contains a port.
string = string.split(":")[0]
domain_processing(string.strip().replace("www.", ""))
def domain_processing(domain):
# Logic for processing after domain extraction, determining if the domain is a root domain; if not, add it to the subdomain list.
# Determine if it is a wildcard domain; there are two forms of wildcards, one is directly removing the preceding `*.` from `*.xxx.yyy.com`, while other formats like `*aaa.com` or `aaa.*` retain their original form.
domain = domain.lstrip("*.") if "*" in domain and domain.startswith("*.") else domain
root_domain = tldextract.extract(domain).registered_domain.strip()
if len(root_domain) and root_domain not in root_domain_list:
root_domain_list.append(root_domain)
if domain != root_domain and domain not in subdomain_list:
subdomain_list.append(domain)
def extract_ip_from_re_ip(re_ip):
# Extract IP from re_ip list.
if len(re_ip) == 1:
# If it is a pure IP, just add the IP to the IP list.
addip_to_ip_list(re_ip[0].strip())
else:
# If more than one IP is matched, add to ip_list in batches.
for ip in re_ip:
addip_to_ip_list(ip.strip())
def addip_to_ip_list(ip):
# Add IP to IP list.
ip = ip.strip()
if ip not in ip_list:
ip_list.append(ip)
def addurl_to_url_list(line):
# Process the http link passed in, adding it to the http link list.
if line.strip() not in url_list:
url_list.append(line.strip())
def addhttp_and_addurl_to_url_list(line):
# For strings containing ports or URLs without HTTP headers, add http for processing.
url = "http://{}".format(line)
addurl_to_url_list(url)
def http_domain_url_extract(url):
# Extract URLs from strings containing HTTP headers and domains.
re_url = re.findall(re.compile(
r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'), url)
if re_url and "." in re_url[0]:
# Adding a dot check, because sometimes the HTTP link matching mechanism is not complete, and erroneous links like http://pay-p may also be recognized.
addurl_to_url_list(re_url[0].strip())
domain_extract(re_url[0].strip())
# Various possible formats, sorted by the actual processing order of the script.
# www.baidu.com
# www.baidu.com/1.html
# www.baidu.com:81
# Garbled characters
# http://www.baidu.com
# http://www.baidu.com:81
# http://11.22.33.44
# http://11.22.33.44:81
# 11.22.33.44:81
# 11.22.33.44
for line in line_list:
try:
re_http = re.findall(r"http[s]?://", line)
re_ip = re.findall(r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}", line)
if not re_http and not re_ip and "." in line:
# Non-http link, and does not contain IP; this part includes pure domain and links without HTTP headers and domains with ports, filtering out special characters, then extracting the domain.
if line.endswith("/"):
line.rstrip("/")
domain_extract(line)
addhttp_and_addurl_to_url_list(line)
elif re_http and not re_ip and "." in line:
# HTTP link but does not contain IP, directly extract the link and domain.
if len(re_http) == 1:
# If there is only one link.
http_domain_url_extract(line.strip())
else:
# If there are multiple links in the same line, first add a space before all http, then split by space.
re_url_list = re.sub("http", " http", line).split()
for url in re_url_list:
http_domain_url_extract(url.strip())
elif re_http and re_ip and "." in line:
# Handle cases with both http and IP, such as: http://222.33.44.55 or http://11.22.33.44:81; just extract the IP and add the link.
extract_ip_from_re_ip(re_ip)
addurl_to_url_list(line)
elif not re_http and re_ip and "." in line:
# Filter strings that do not contain http but contain IP.
if ":" not in line:
# Filter pure IP, add to IP address list.
extract_ip_from_re_ip(re_ip)
else:
# Filter IP:PORT special form; the logic here is a bit complex.
# If multiple IP:PORTs are connected together, it is impossible to match multiple IPs, so if there are multiple IP:PORTs, there must be a gap in between.
re_ip_port = re.findall(
r"^(?:[0-9]{1,3}\.){3}[0-9]{1,3}\:\d+", line)
if len(re_ip) == 1:
# If it is a pure IP,
addip_to_ip_list(re_ip[0].strip())
else:
# If more than one IP is matched, add to ip_list in batches.
for ip in re_ip:
addip_to_ip_list(ip.strip())
if re_ip_port:
if len(re_ip_port) == 1:
ip_port = re_ip_port[0].strip()
addhttp_and_addurl_to_url_list(ip_port)
else:
# There are multiple IP:PORT special forms.
for i in re_ip_port:
ip_port = i.strip()
addhttp_and_addurl_to_url_list(ip_port)
if len(re_ip) != len(re_ip_port):
print("The number of IPs and IP:PORTs is not equal.")
else:
print("Special string: {}".format(line))
except Exception as e:
continue
# Sort IP addresses.
ip_list = sorted(ip_list, key=socket.inet_aton)
# Result aggregation.
dividing_line = "-"*60
results_content = "\t\troot domain list as follows\n{}\n{}\n{}\n\t\tsubdomain list as follows\n{}\n{}\n{}\n\t\tip list as follows\n{}\n{}\n{}\n\t\turl list as follows\n{}\n{}\n".format(
dividing_line, "\n".join(root_domain_list), dividing_line, dividing_line, "\n".join(subdomain_list), dividing_line, dividing_line, "\n".join(ip_list), dividing_line, dividing_line, "\n".join(url_list))
results_save_path = "parsed_asset.txt"
if (os.path.exists(results_save_path)):
os.remove(results_save_path)
with open(results_save_path, "a+") as f:
f.write(results_content)
Script Effect#
The effect is as follows; tested with several exclusive vendors, all can meet expected output.
Taizhou Big Data Development Center#
Zhejiang Mobile Information Security Department#
Usage: directly run python script name followed by file name.
If you have any related suggestions, you can discuss them in the comments section.