Cause#
Recently during my internship, I was required to find a website to scrape and store data into an excel spreadsheet.
I also filter movies based on Douban's TOP250, and manually flipping pages is too cumbersome, so I decided to scrape it.
[2019-09-02 Update] Later, I needed to do an assignment defense, so I changed it to store the data in a mysql database.
Code Implementation#
Unlike most scraping articles online, what I want is the plot summary information for each movie.
So I need to first get the link for each movie, and then scrape each movie individually.
The complete code is as follows:
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: Scraping Douban TOP250 movie information and storing it in a mysql database (multithreading)
@time: 2019-09-01
'''
import requests
from fake_useragent import UserAgent
from lxml import etree
from tqdm import tqdm
import threading
import pymysql
from re import split
"""
If the library is not found, you can copy the following statements to solve it
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fake_useragent
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tqdm
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple threading
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pymysql
"""
class Top250(object):
def __init__(self):
ua = UserAgent() # Used to generate User-Agent
self.headers = {"User-Agent": ua.random} # Get a random User-Agent
self.bangdang_l = [] # Store the pages of the list
self.subject_url_l = [] # Store the link for each movie
self.connect_mysql()
def connect_mysql(self):
# Connect to the database, the password can be followed by the database name
try:
self.mysql_conn = pymysql.connect(
'localhost', 'root', 'root', charset='utf8')
# Get a cursor object that can execute SQL statements, the results returned by default are displayed as tuples
self.cursor = self.mysql_conn.cursor()
print("Database connection successful")
except Exception as e:
print("Database connection error:{}\nWhere do you want me to store the scraped data? Exiting the program!".format(e))
exit(0)
else:
self.create_db()
def create_db(self):
# Create database and table
# Check if the database exists, if it does, delete it and then create it
sql_db_dection = "DROP DATABASE IF EXISTS `douban_top250`"
sql_create_db = "CREATE DATABASE `douban_top250` default charset utf8 COLLATE utf8_general_ci;"
sql_create_table = """
CREATE TABLE `movies_info` (
`Movie Name` varchar(255) NOT NULL,
`Director` varchar(511) NOT NULL,
`Starring Information` varchar(511) NOT NULL,
`Genre` varchar(255) NOT NULL,
`Release Date` varchar(255) NOT NULL,
`Plot Summary` varchar(511) NOT NULL,
`Ranking` varchar(255) NOT NULL,
`Duration` varchar(255) NOT NULL,
PRIMARY KEY (`Ranking`)
)DEFAULT CHARSET=utf8;
"""
try:
self.cursor.execute(sql_db_dection)
self.cursor.execute(sql_create_db)
self.cursor.execute('use douban_top250;') # Set the current database to the newly created database
self.cursor.execute(sql_create_table)
except Exception as e: # Catch all exceptions and print, python2 is Exception,e
print("Database creation error:{}\nExiting the program!".format(e))
self.mysql_conn.rollback() # Rollback on error
self.mysql_conn.close() # Close the database connection
exit(0)
else:
print("Database and table created successfully, starting to scrape each movie's link..")
self.get_subject_url()
def get_subject_url(self):
# Iterate through the 250 list to get individual links for each movie
self.bangdang_l = [
"https://movie.douban.com/top250?start={}&filter=".format(i) for i in range(0, 250, 25)]
self.multi_thread(self.bangdang_l, self.crawl_bangdang)
if len(self.subject_url_l) == 0:
print("IP has been blocked, exiting the program")
exit(0)
else:
print("{} TOP movie links have been successfully obtained, starting to scrape individual movies, please wait...".format(
len(self.subject_url_l)))
self.multi_thread(self.subject_url_l, self.get_one_movie_info)
def crawl_bangdang(self, url):
# Scrape the movie links from each list page
try:
req = requests.get(url, headers=self.headers)
req.encoding = "utf-8"
html = etree.HTML(req.text)
# Get the list of all a tags
url_l = html.xpath('//div[@class="hd"]//a/@href')
self.subject_url_l.extend(url_l)
except Exception as e:
print("Error while scraping list information: {}".format(e))
else:
print("Successfully obtained list data from page {}...\n".format(
int(int(split(r"=|&", url)[1])/25 + 1)))
def multi_thread(self, url_l, target_func):
# Multithreading scraping function, passing in the list of URLs to scrape and the function to use for scraping
threads = []
for i in range(len(url_l)):
t = threading.Thread(target=target_func, args=(url_l[i],))
threads.append(t)
for i in range(len(threads)):
threads[i].start()
for i in range(len(threads)):
threads[i].join()
print("Scraping completed")
def get_one_movie_info(self, subject):
# Function to scrape a single URL
try:
req = requests.get(subject, headers=self.headers)
html = etree.HTML(req.content)
except Exception as e:
print("Scraping error:".format(e))
else:
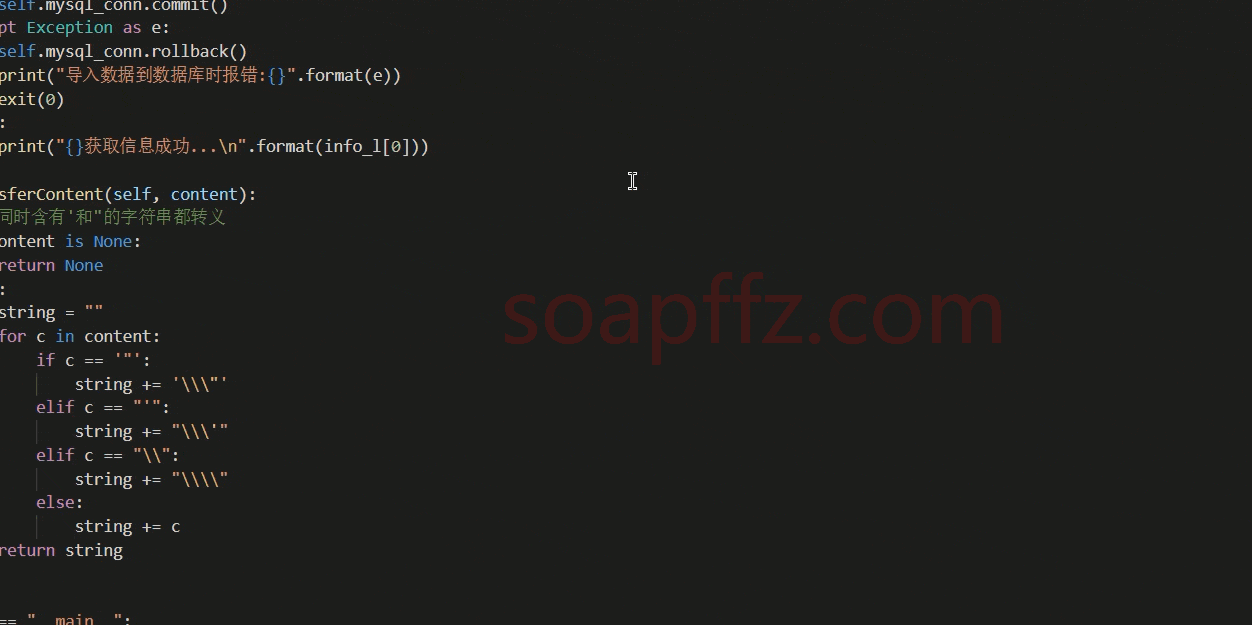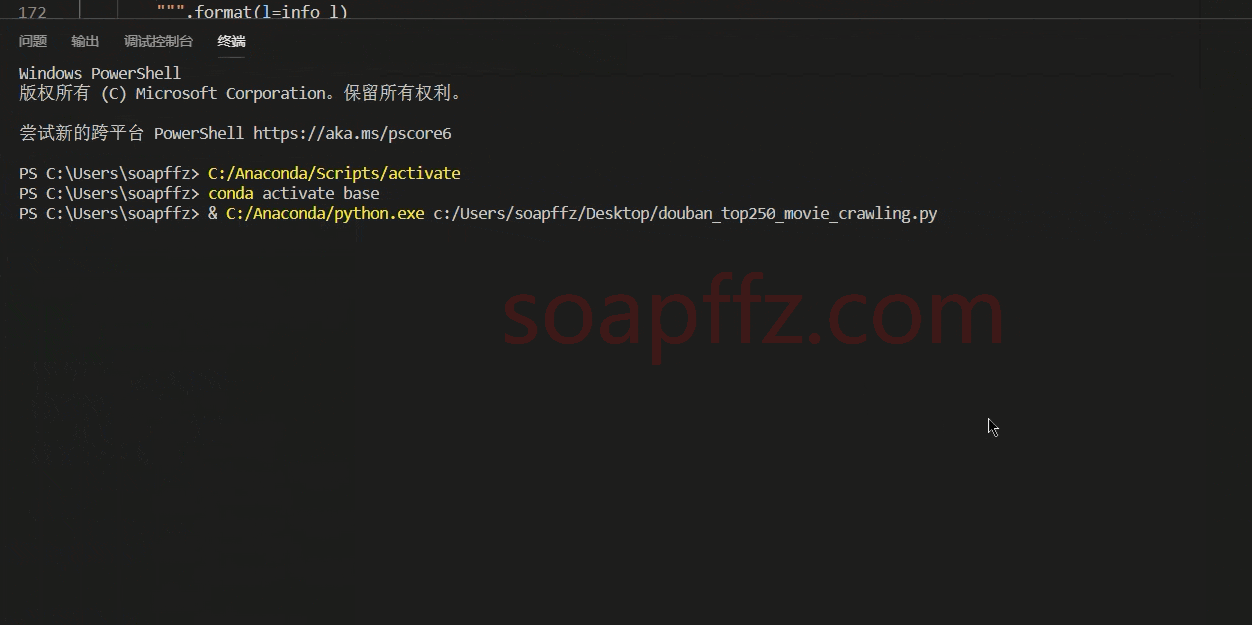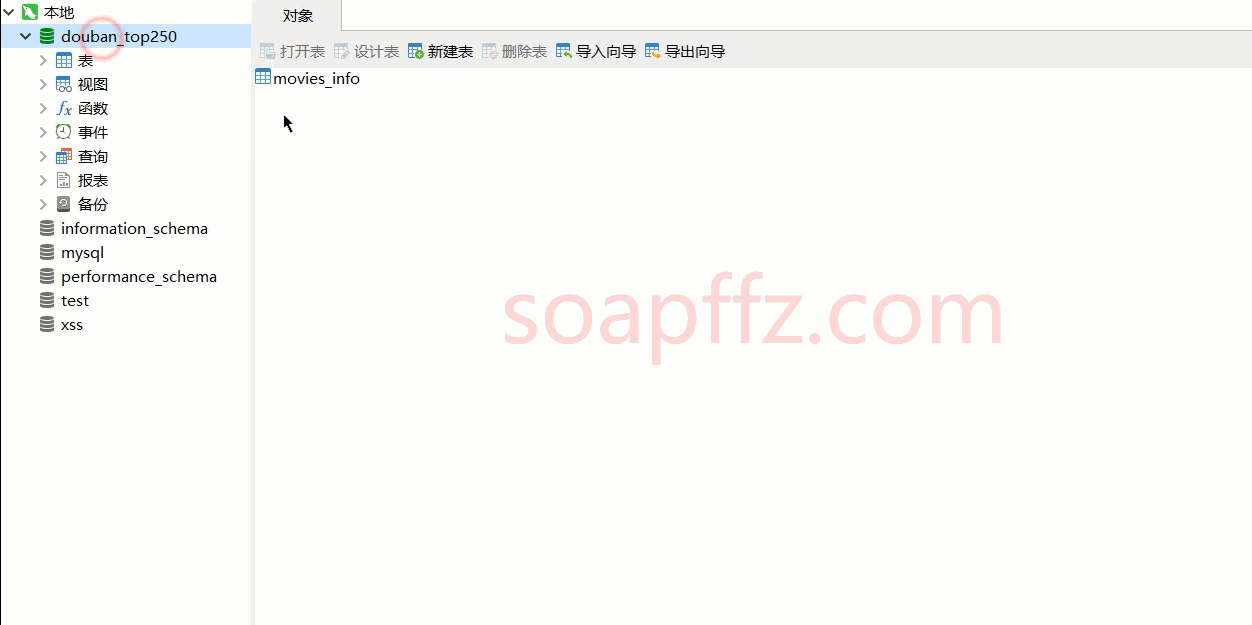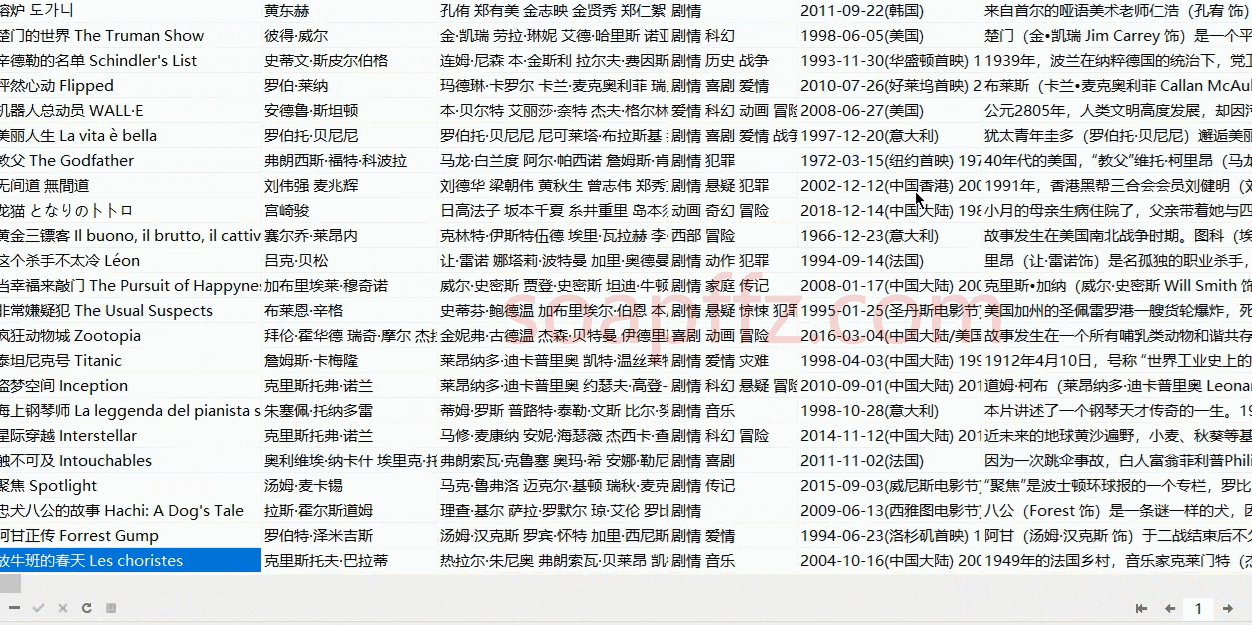
# Used to store information about a single movie
info = []
# Movie name information
movie_name = html.xpath(
"//span[@property='v:itemreviewed']/text()")
info.append(" ".join(movie_name))
# Director information
director = html.xpath("//a[@rel='v:directedBy']//text()")
info.append(" ".join(director))
# Starring information
actor = html.xpath("//a[@rel='v:starring']//text()")
info.append(" ".join(actor))
# Genre
genre = html.xpath("//span[@property='v:genre']/text()")
info.append(" ".join(genre))
# Release date
initialReleaseDate = html.xpath(
"//span[@property='v:initialReleaseDate']/text()")
info.append(" ".join(initialReleaseDate))
# Plot summary
reated_info = html.xpath("//span[@class='all hidden']/text()")
# Some plot summaries are hidden, by default get the hidden tags, if not hidden get the non-hidden tags
if len(reated_info) == 0:
reated_info = html.xpath(
"//span[@property='v:summary']/text()")
reated_info = "".join([s.strip() for s in reated_info]).strip("\\")
reated_info = self.transferContent(reated_info)
info.append(reated_info)
# Ranking
no = html.xpath("//span[@class='top250-no']/text()")
if len(no) == 1:
info.append(no[0].split(".")[-1])
else:
info.append("Failed to retrieve")
runtime = html.xpath("//span[@property='v:runtime']/text()")
if len(runtime) == 1:
info.append(runtime[0].split("minutes")[0])
else:
info.append("Failed to retrieve")
self.db_insert(info)
def db_insert(self, info_l):
sql_insert_detection = """
insert ignore into `douban_top250`.`movies_info` (`Movie Name`,`Director`,`Starring Information`,`Genre`,`Release Date`,`Plot Summary`,`Ranking`,`Duration`)
values ("{l[0]}","{l[1]}","{l[2]}","{l[3]}","{l[4]}","{l[5]}","{l[6]}","{l[7]}");
""".format(l=info_l)
try:
self.cursor.execute(sql_insert_detection)
self.mysql_conn.commit()
except Exception as e:
self.mysql_conn.rollback()
print("Error while importing data to the database:{}".format(e))
exit(0)
else:
print("{} information retrieved successfully...\n".format(info_l[0]))
def transferContent(self, content):
# Escape strings that contain both ' and "
if content is None:
return None
else:
string = ""
for c in content:
if c == '"':
string += '\\\"'
elif c == "'":
string += "\\\'"
elif c == "\\":
string += "\\\\"
else:
string += c
return string
if __name__ == "__main__":
Top250()
The demonstration gif is as follows:
Reference articles: