Introduction#
Whether it's brute force cracking or anti-crawling, a proxy pool is an essential condition.
Regarding the acquisition of proxy pools, we have already introduced it in the previous article: "Multi-threaded Crawling of Xici High-Anonymity Proxies and Validating Usability."
We will use the validated proxies obtained from that article to try to increase page views.
Ugly Code Implementation#
Most of the code implementation is directly copied from the aforementioned article.
The only difference is that I learned about a library called fake_useragent, which can be used to generate random User-Agents. A simple example code is as follows:
from fake_useragent import UserAgent
ua = UserAgent() # Used to generate User-Agent
headers = {"User-Agent": ua.random} # Get a random User-Agent
print(headers)
For specifying the browser's User-Agent, you can refer to this article: https://blog.csdn.net/qq_29186489/article/details/78496747
Full code:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: Using Proxy IP Pool to Increase Page Views
@time: 2019-01-23
'''
import os
import requests
from fake_useragent import UserAgent
from multiprocessing import Pool
import timeit
url = "https://soapffz.com/" # The webpage to be accessed
ua = UserAgent() # Used to generate User-Agent
path = os.path.join(os.path.expanduser("~")+"\\")
http_proxy_path = os.path.join(
path+"Desktop"+"\\"+"http_proxy.txt") # This is the location of my own proxy IP
https_proxy_path = os.path.join(
path+"Desktop"+"\\"+"https_proxy.txt") # Modify according to your own location
http_proxy = [] # Store http proxies
https_proxy = [] # Store https proxies
def brush_visits(proxies):
proxy_type = proxies.split(":")[0]
if proxy_type == 'http':
proxy = {'http': proxies}
else:
proxy = {'https': proxies}
headers = {"User-Agent": ua.random} # Get a random User-Agent
req = requests.get(url, headers=headers, proxies=proxy, timeout=10)
if req.status_code == 200:
print("This proxy accessed successfully: {}".format(proxies))
if __name__ == "__main__":
start_time = timeit.default_timer()
if not os.path.exists(http_proxy_path):
print("You want to increase page views without preparing proxies? Get lost!")
os._exit(0)
with open(http_proxy_path, 'r') as f:
http_proxy = f.read().splitlines()
with open(https_proxy_path, 'r') as f:
https_proxy = f.read().splitlines()
pool1 = Pool()
pool2 = Pool()
for proxies in http_proxy:
pool1.apply_async(brush_visits, args=(proxies,))
for proxies in https_proxy:
pool2.apply_async(brush_visits, args=(proxies,))
pool1.close()
pool2.close()
pool1.join()
pool2.join()
end_time = timeit.default_timer()
print("The proxy pool has been exhausted, total time taken: {}s".format(end_time-start_time))
The effect is shown below:
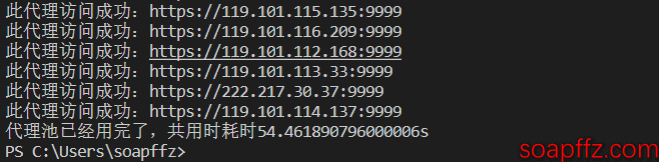
Update#
[2019-08-27 Update] The previous implementation was based on file reading, which seems a bit silly now. Given the recent demand for this, I will update it.
The only preparation needed is to install the Mongodb database, which you can refer to in my previous article "Installing MongoDB on Win10."
Then you can run this code directly, modifying the interface you want to access. The full code is as follows:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: Using Proxy IP Pool to Batch Access Website Views (Reading Proxy Collection from Local MongoDB Database)
@time: 2019-08-27
'''
from os import popen
from threading import Thread # Multi-threading
from pymongo import MongoClient
from requests import get
from lxml import etree # Parse the site
from re import split # Regex parsing library
from telnetlib import Telnet # Telnet connection test for proxy validity
from fake_useragent import UserAgent
from multiprocessing import Pool
def brush_visits(url, proxy):
# Access a single page with a single proxy
try:
ua = UserAgent() # Used to generate User-Agent
headers = {"User-Agent": ua.random} # Get a random User-Agent
req = get(url, headers=headers, proxies=proxy, timeout=0.3)
if req.status_code == 200:
print("This proxy {} contributed a visit".format(proxy))
except Exception as e:
pass
class batch_brush_visits(object):
def __init__(self, url):
self.url = url
self.ua = UserAgent() # Used to generate User-Agent
self.run_time = 0 # Number of runs
self.conn_db()
self.get_proxies_l()
def conn_db(self):
# Connect to the database
try:
# Connect to MongoDB and get the connection object
self.client = MongoClient('mongodb://localhost:27017/').proxies
self.db = self.client.xici # Specify the proxies database; this class uses this database, and it won't be created automatically if there's no data
self.refresh_proxies()
except Exception as e:
print("Database connection error")
exit(0)
def refresh_proxies(self):
if "xici" in self.client.list_collection_names():
# Delete existing collections each time during initialization
self.db.drop()
t = Thread(target=self.xici_nn_proxy_start)
t.start()
t.join()
def get_proxies_l(self):
# Read the corresponding collection for IP and port information
collection_dict_l = self.db.find(
{}, {"_id": 0, "ip": 1, "port": 1, "type": 1})
self.proxies_l = []
for item in collection_dict_l:
if item["type"] == 'http':
self.proxies_l.append(
{"http": "{}:{}".format(item['ip'], item['port'])})
else:
self.proxies_l.append(
{"https": "{}:{}".format(item['ip'], item['port'])})
if len(self.proxies_l) == 0:
print("No proxies obtained, what a waste...")
exit(0)
else:
self.brush_visits_start()
def xici_nn_proxy_start(self):
xici_t_cw_l = [] # Crawling thread list
self.xici_crawled_proxies_l = [] # Clear before each crawl
for i in range(1, 11): # Crawl 10 pages of proxies
t = Thread(target=self.xici_nn_proxy, args=(i,))
xici_t_cw_l.append(t) # Add thread to thread list
t.start()
for t in xici_t_cw_l: # Wait for all threads to complete before exiting the main thread
t.join()
# Insert into the database
self.db_insert(self.xici_crawled_proxies_l)
def xici_nn_proxy(self, page):
# Xici proxy crawling function
url = "https://www.xicidaili.com/nn/{}".format(page)
# Not adding user-agent here will return status code 503
req = get(url, headers={"User-Agent": self.ua.random})
if req.status_code == 200:
# Other status codes indicate the IP is blocked
content = req.content.decode("utf-8")
tree = etree.HTML(content)
# Use xpath to get the total ip_list
tr_nodes = tree.xpath('.//table[@id="ip_list"]/tr')[1:]
for tr_node in tr_nodes:
td_nodes = tr_node.xpath('./td') # Use xpath to get the tag of a single IP
speed = int(split(r":|%", td_nodes[6].xpath(
'./div/div/@style')[0])[1]) # Get the speed value
conn_time = int(split(r":|%", td_nodes[7].xpath(
'./div/div/@style')[0])[1]) # Get the connection time value
if(speed <= 85 | conn_time <= 85): # If speed and connection time are not ideal, skip this proxy
continue
ip = td_nodes[1].text
port = td_nodes[2].text
ip_type = td_nodes[5].text.lower()
self.get_usable_proxy(ip, port, ip_type, "xici")
def get_usable_proxy(self, ip, port, ip_type, proxy_name):
proxies_l = {"ip": ip, "port": port, "type": ip_type}
if proxies_l not in self.xici_crawled_proxies_l:
try:
# Use telnet to connect; if it connects, the proxy is usable
Telnet(ip, port, timeout=0.3)
except:
pass
else:
self.xici_crawled_proxies_l.append(proxies_l)
def db_insert(self, proxies_list):
if proxies_list:
# Exit if the passed list is empty
self.db.insert_many(proxies_list) # Insert a list of dictionaries
print(
"Data insertion completed!\nA total of {} proxies inserted into the xici collection!".format(len(proxies_list)))
else:
print(
"The crawled proxy list is empty!\nIf you see this message quickly\nThe IP is likely blocked\nPlease use a VPN!\nOtherwise, the latest proxies are already in the database\nNo need to crawl again!")
def brush_visits_start(self):
# Use the obtained proxies to access the page
try:
self.run_time += 1
pool = Pool()
for proxy in self.proxies_l:
pool.apply_async(brush_visits(self.url, proxy))
pool.close()
pool.join()
if self.run_time == 100:
print("Accessed a hundred times, refreshing proxies")
self.refresh_proxies()
print("Completed one round of access")
self.brush_visits_start()
except Exception as e:
print("Program encountered an error and exited:{}".format(e))
exit(0)
if __name__ == "__main__":
url = "https://soapffz.com/3.html" # Fill in the URL you want to access here
batch_brush_visits(url)
The effect is as follows:
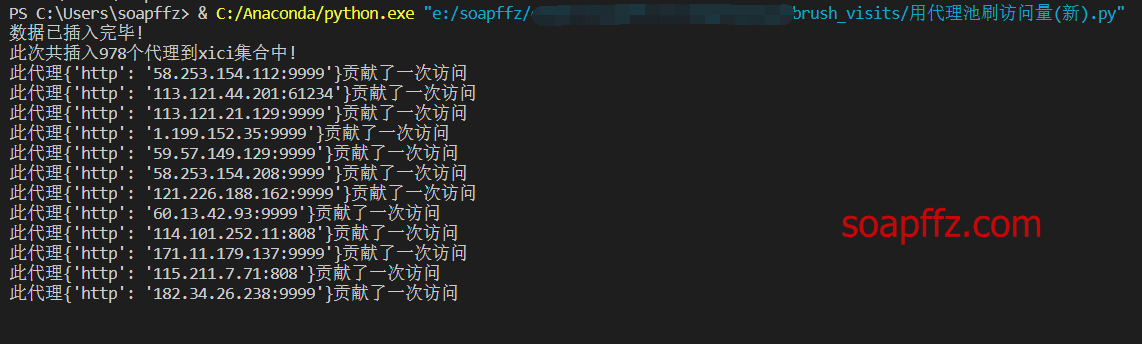
Additionally, the code in this article is designed to access one url. If you need to access multiple urls simultaneously, you will need to use the Cartesian product. An example is as follows:
from itertools import product
urls_l = ["https://soapffz.com/279.html",
"https://soapffz.com/timeline.html", "https://soapffz.com/372.html"]
proxies_l = ["120.120.120.121", "1.1.1.1", "231.220.15.2"]
paramlist = list(product(urls_l, proxies_l))
for i in range(len(paramlist)):
print(paramlist[i])
The effect is as follows:
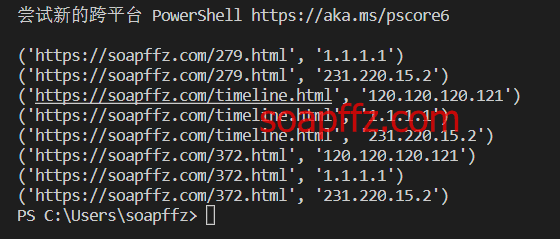
So, you need to make the following changes:
- Import this library:
from itertools import product
- Change the
urlin themainfunction to a list
if __name__ == "__main__":
urls_l = ["https://soapffz.com/3.html"] # Fill in the list of URLs you want to access here
batch_brush_visits(urls_l)
- Change the access target to the Cartesian product
The brush_visits_start part of the batch_brush_visits class should be modified as follows:
pool = Pool()
for proxy in self.proxies_l:
pool.apply_async(brush_visits(self.url, proxy))
pool.close()
pool.join()
Change to
paramlist = list(product(self.urls_l, self.proxies_l))
pool = Pool()
for i in range(len(paramlist)):
pool.apply_async(brush_visits(paramlist[i]))
pool.close()
pool.join()
- Modify the access function
The brush_visits function should be modified as follows, from
def brush_visits(url, proxy):
# Use a single proxy to access a single page
try:
ua = UserAgent() # Used to generate User-Agent
headers = {"User-Agent": ua.random} # Get a random User-Agent
req = get(url, headers=headers, proxies=proxy, timeout=0.3)
if req.status_code == 200:
print("This proxy {} contributed a visit".format(proxy))
except Exception as e:
pass
To:
def brush_visits(paramlist):
# Use a single proxy to access a single page
try:
url = paramlist[0]
proxy = paramlist[1]
ua = UserAgent() # Used to generate User-Agent
headers = {"User-Agent": ua.random} # Get a random User-Agent
req = get(url, headers=headers, proxies=proxy, timeout=0.3)
if req.status_code == 200:
print("This proxy:{} contributed a visit".format(proxy))
except Exception as e:
pass
That's about it; you can achieve the effect of each proxy accessing each url once.
The article ends here.