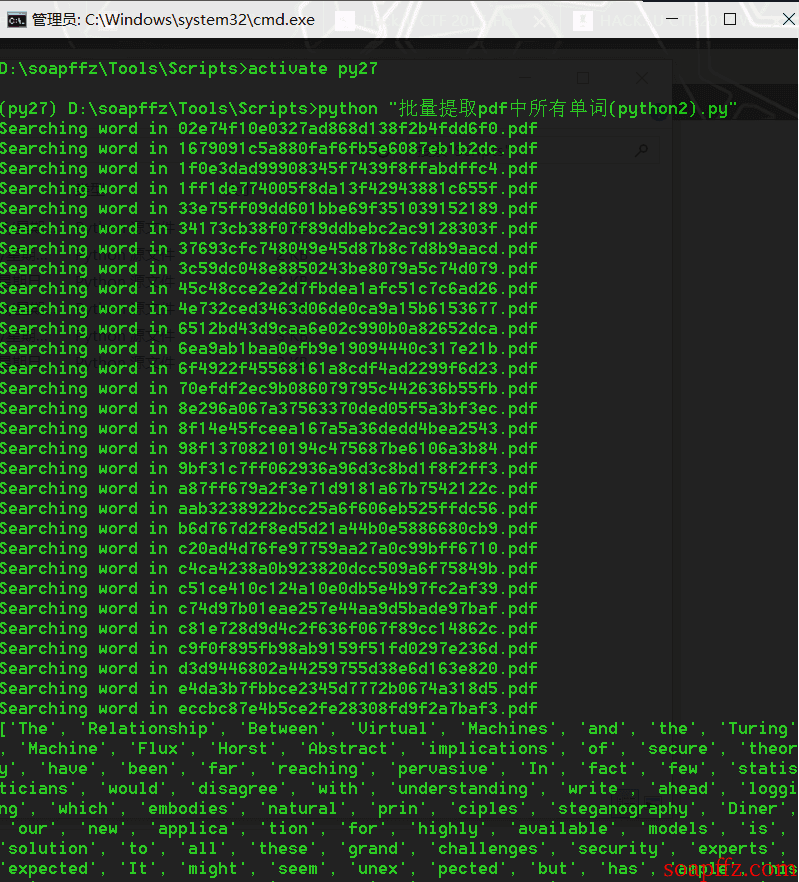
このコードは、Hack.lu CTF 2017-Flatscience-writeup のために補完されました。リンク#
# !/usr/bin/python
# - * - coding:utf-8 - * -
'''
@author: soapffz
@fucntion: 批量提取pdf中所有单词(python2)
@time: 2019-01-06
'''
from cStringIO import StringIO
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
import os
import re
def convert(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec = 'utf-8', laparams = LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
with open(path, 'rb')as fp:
for page in PDFPage.get_pages(fp, set()):
interpreter.process_page(page)
text = retstr.getvalue()
device.close()
retstr.close()
return text
def main(path):
os.chdir(path)# 切换工作目录
pdf_path = [i for i in os.listdir("./")if i.endswith("pdf")]
words_list = []
for i in pdf_path:
print "Searching word in " + i
pdf_text = convert(i)
words = re.findall('[A-Za-z]+', pdf_text)
for i in words:
if i not in words_list:
words_list.append(i)
#print words_list
# 返回包含所有单词的一个list
return words_list
if __name__ == "__main__":
path = r"C:\Users\soapffz\Desktop\to_dir"
# 注意复制的目录前面可能有一个看不见的特殊符号
main(path)
効果は以下の通りです:#