2021-12-08 凌晨更新
添加了两行代码
- 添加初始字符串处理,不包含点
.的直接去除,因为不管是域名还是 IP 都一定包含.,大幅降低了特殊字符串报告频率 - 处理了一般通配符例如
*.10bis.co.il,这种直接去除前面的 *.,其他的格式比如*aaa.com或者aaa.\*这些格式保留原样
代码已直接更新在下面的代码块中
是的,快一年没更新,终于来水一篇文
脚本诞生的意义#
众所周知,脚本,尤其是 Python 或者 go 小脚本,是比较适合用来处理一些简单信息的
在针对 SRC 进行挖掘的时候,常常会遇到,部分厂商,直接丢了一大段文字,或者直接丢个 Excel,说这是测试范围(非范围内容)
而且还常常包含中文,中文标点,IP,内容杂乱无章
所以写了个脚本,处理这类资产,整理输出
输入 txt 可以包含中文,中文标点,域名,IP,任意杂乱字符
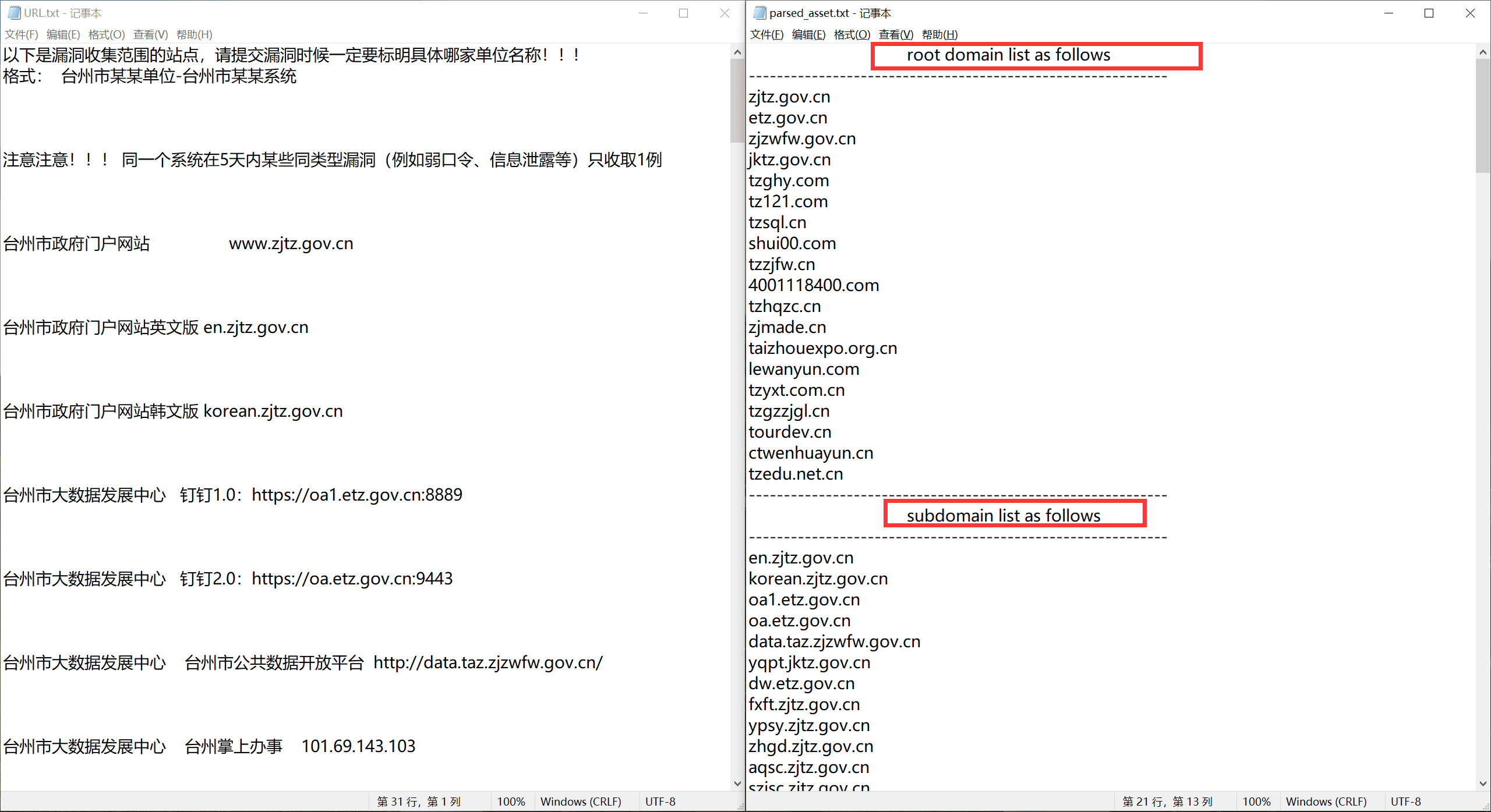
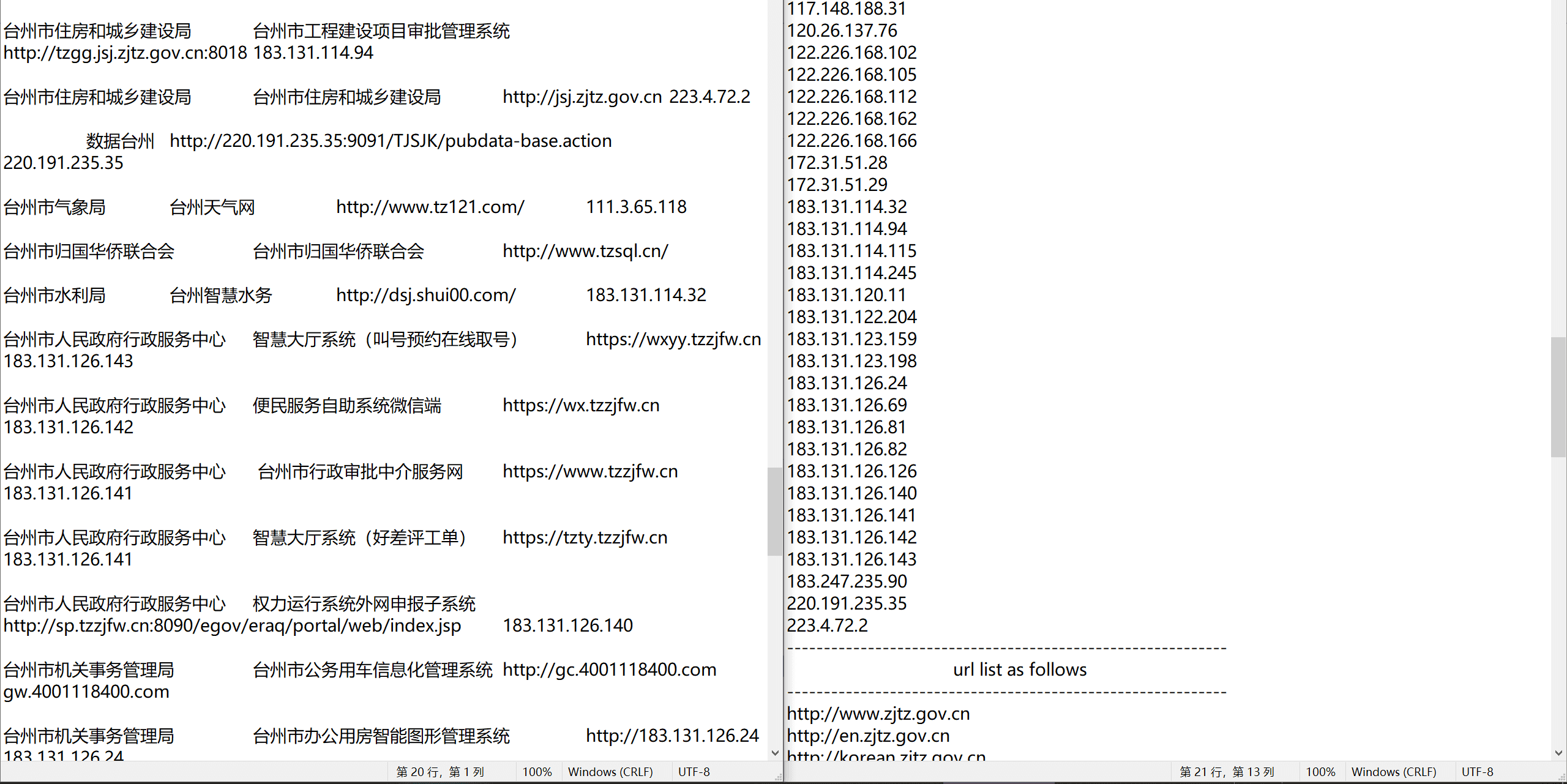
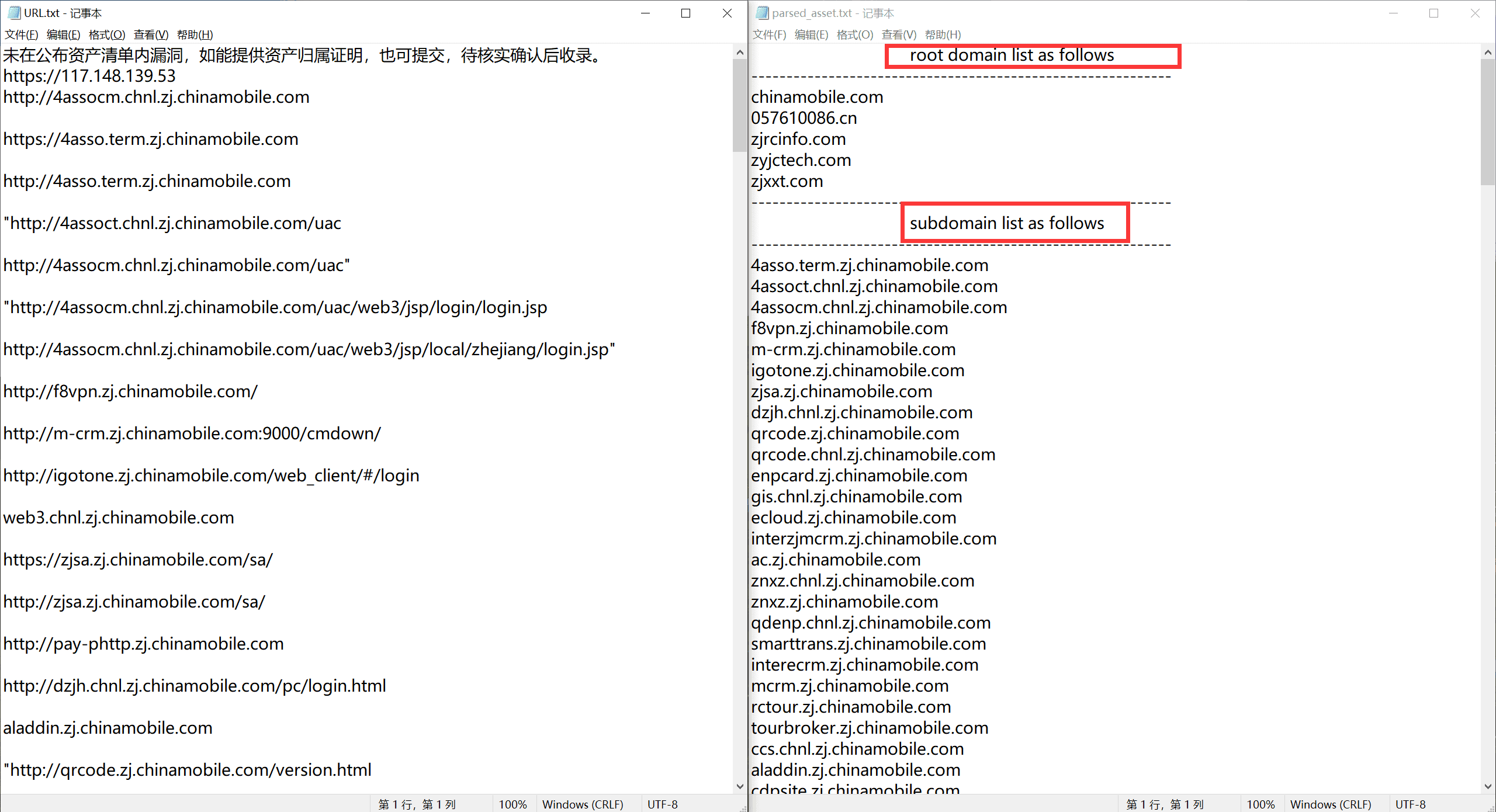
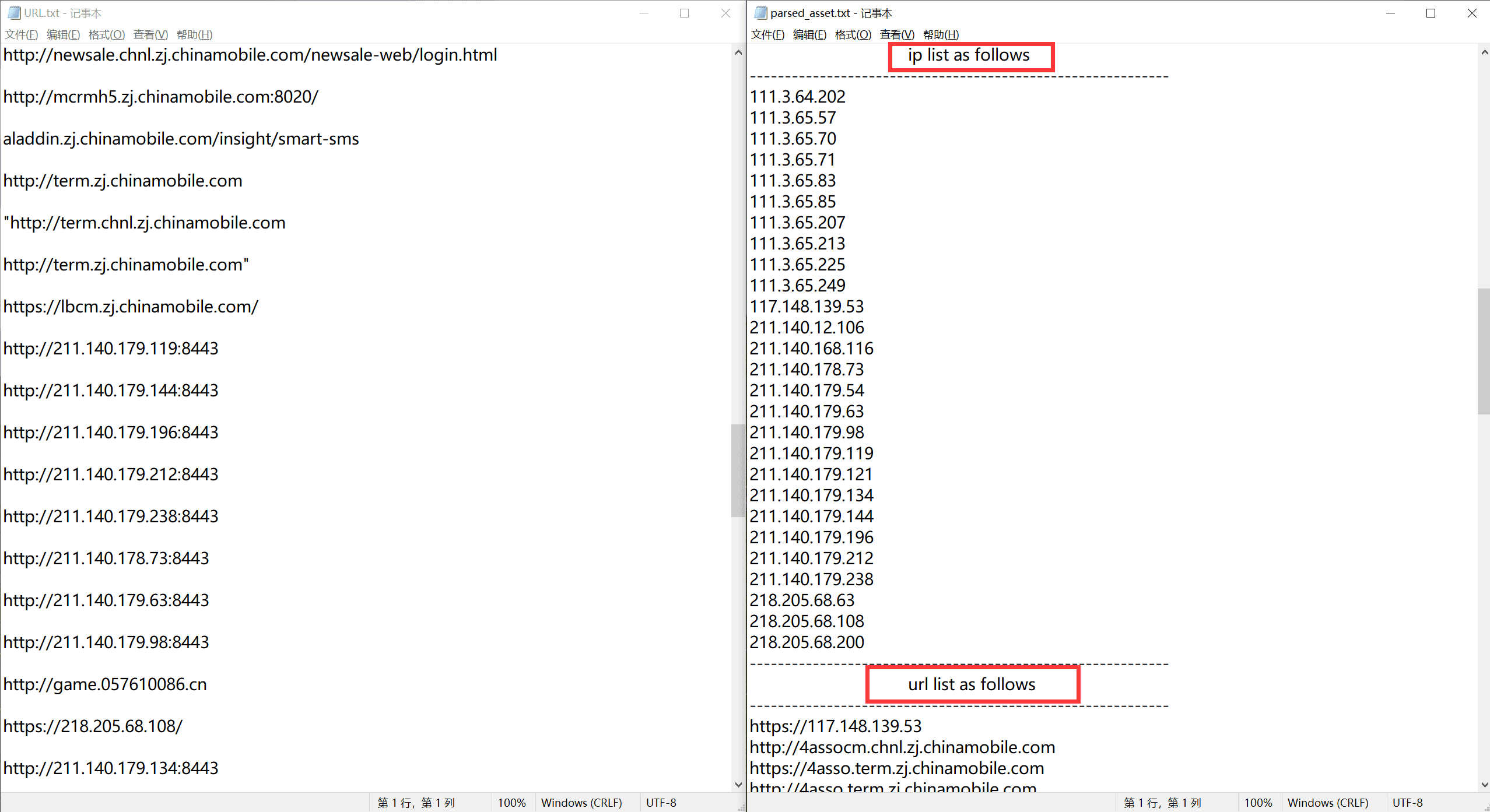
输出 txt 按顺序包含根域名,子域名,IP 地址(排序过的),以及 URL 链接
话不多说,直接放脚本
脚本#
#!/usr/bin/env python
# 资产信息整理,原格式可以为包含中文及中文标点的IP、URL、http链接,也可以包含单个IP或者子域名
# 提取后包含纯域名、根域名合集、URL合计、纯IP
import tldextract
import re
import sys
from urllib.parse import urlparse
from zhon.hanzi import punctuation
import socket
import os
if len(sys.argv) != 2:
print("还没指定文件!")
exit(0)
subdomain_list, root_domain_list, ip_list, url_list = [], [], [], []
# 读取原本文件内容,去除空行
origin_file_content = re.sub(
r"\n[\s| ]*\n", '', open(str(sys.argv[1]), "r", encoding="utf-8").read())
# 去除中文文字
content_without_chs = re.sub('[\u4e00-\u9fa5]', '', origin_file_content)
# 去除中文标点
content_without_chs_punctuation = re.sub(
'[{}]'.format(punctuation), "", content_without_chs)
# 整理格式为单行,去除前后多余空格
line_list = re.sub("http", " http", content_without_chs_punctuation).split()
# 去除不包含点的行.,因为不管是什么格式,一定都有.在行中
line_list = [line.strip() for line in line_list if "." in line]
# 文件太大的话,就报错,直接退出程序
if len(line_list) > 100000:
print("当前文本解析条数过大,不建议使用该脚本,会卡,建议分批次使用本脚本")
print("当然,你要想现在写个文本分割脚本也行")
exit(0)
# for line in line_list:
# print(line)
# exit(0)
def domain_extract(string):
# 从URL中提取域名的函数,传入URL或者纯域名
if bool(re.search(r"[a-zA-Z]", string)) and "." in string:
# 不包含字母的字符串过滤掉,不包含.符号的过滤掉
if "http" in string:
# URL处理方式
domain = urlparse(string).netloc.strip()
if len(domain) and bool(re.search(r"[a-zA-Z]", domain)):
if ":" in domain:
# 包含端口的传进来的URL,把端口去掉
domain = domain.split(":")[0]
domain_processing(domain.strip().replace("www.", ""))
else:
# 纯域名处理方式
if ":" in string:
# 包含端口的传进来的URL,把端口去掉
string = string.split(":")[0]
domain_processing(string.strip().replace("www.", ""))
def domain_processing(domain):
# 域名提取后的处理逻辑,判断域名是否为根域名,不是则加入子域名列表
# 判断是否为通配符域名,通配符有两种形式,一种是直接*.xxx.yyy.com去掉前面的通配符,其他格式比如*aaa.com或者aaa.*这些格式保留原样
domain = domain.lstrip("*.") if "*" in domain and domain.startswith("*.") else domain
root_domain = tldextract.extract(domain).registered_domain.strip()
if len(root_domain) and root_domain not in root_domain_list:
root_domain_list.append(root_domain)
if domain != root_domain and domain not in subdomain_list:
subdomain_list.append(domain)
def extract_ip_from_re_ip(re_ip):
# 从re_ip列表中提取IP
if len(re_ip) == 1:
# 如果为纯IP,添加IP到IP列表即可
addip_to_ip_list(re_ip[0].strip())
else:
# 如果匹配到了不止一个IP,则分批次加入ip_list
for ip in re_ip:
addip_to_ip_list(ip.strip())
def addip_to_ip_list(ip):
# 添加IP至IP列表
ip = ip.strip()
if ip not in ip_list:
ip_list.append(ip)
def addurl_to_url_list(line):
# 传入http链接,进行http链接列表处理
if line.strip() not in url_list:
url_list.append(line.strip())
def addhttp_and_addurl_to_url_list(line):
# 对于包含端口的字符串或者无HTTP头的url链接,加上http进行处理
url = "http://{}".format(line)
addurl_to_url_list(url)
def http_domain_url_extract(url):
# 提取包含http头且为域名的字符串中的URL
re_url = re.findall(re.compile(
r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'), url)
if re_url and "." in re_url[0]:
# 加一个.判断,是因为有时候http链接匹配机制不完全,有可能http://pay-p这样的错误链接也被识别
addurl_to_url_list(re_url[0].strip())
domain_extract(re_url[0].strip())
# 各种可能出现的格式,按脚本实际处理先后顺序排序
# www.baidu.com
# www.baidu.com/1.html
# www.baidu.com:81
# 乱码字符
# http://www.baidu.com
# http://www.baidu.com:81
# http://11.22.33.44
# http://11.22.33.44:81
# 11.22.33.44:81
# 11.22.33.44
for line in line_list:
try:
re_http = re.findall(r"http[s]?://", line)
re_ip = re.findall(r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}", line)
if not re_http and not re_ip and "." in line:
# 非http链接,也不包含IP,该部分包含纯域名及无HTTP头链接及域名后面加端口,过滤掉特殊字符,然后提取域名
if line.endswith("/"):
line.rstrip("/")
domain_extract(line)
addhttp_and_addurl_to_url_list(line)
elif re_http and not re_ip and "." in line:
# HTTP链接但是不包含IP,直接提取链接和域名
if len(re_http) == 1:
# 如果只有一条链接
http_domain_url_extract(line.strip())
else:
# 如果有多条链接在同一行,先在所有http前面加上空格,再以空格分离
re_url_list = re.sub("http", " http", line).split()
for url in re_url_list:
http_domain_url_extract(url.strip())
elif re_http and re_ip and "." in line:
# 处理既有http又有IP,即:http://222.33.44.55或http://11.22.33.44:81的格式,只需要提取IP及加入链接即可
extract_ip_from_re_ip(re_ip)
addurl_to_url_list(line)
elif not re_http and re_ip and "." in line:
# 筛选不包含http但是包含IP的字符串
if ":" not in line:
# 筛选纯IP,加入IP地址列表
extract_ip_from_re_ip(re_ip)
else:
# 筛选IP:PORT特殊形式,这的逻辑稍稍有些复杂
# 如果是多条IP:PORT连在一起,是不可能匹配到多个IP的,所以如果是多条IP:PORT,中间一定是有间隔的
re_ip_port = re.findall(
r"^(?:[0-9]{1,3}\.){3}[0-9]{1,3}\:\d+", line)
if len(re_ip) == 1:
# 如果为纯IP,
addip_to_ip_list(re_ip[0].strip())
else:
# 如果匹配到了不止一个IP,则分批次加入ip_list
for ip in re_ip:
addip_to_ip_list(ip.strip())
if re_ip_port:
if len(re_ip_port) == 1:
ip_port = re_ip_port[0].strip()
addhttp_and_addurl_to_url_list(ip_port)
else:
# 有多条IP:PORT的特殊形式,这个币
for i in re_ip_port:
ip_port = i.strip()
addhttp_and_addurl_to_url_list(ip_port)
if len(re_ip) != len(re_ip_port):
print("出现IP和IP:PORT数量不等的情况")
else:
print("特殊字符串:{}".format(line))
except Exception as e:
continue
# IP地址排序
ip_list = sorted(ip_list, key=socket.inet_aton)
# 结果聚合
dividing_line = "-"*60
results_content = "\t\troot domain list as follows\n{}\n{}\n{}\n\t\tsubdomain list as follows\n{}\n{}\n{}\n\t\tip list as follows\n{}\n{}\n{}\n\t\turl list as follows\n{}\n{}\n".format(
dividing_line, "\n".join(root_domain_list), dividing_line, dividing_line, "\n".join(subdomain_list), dividing_line, dividing_line, "\n".join(ip_list), dividing_line, dividing_line, "\n".join(url_list))
results_save_path = "parsed_asset.txt"
if (os.path.exists(results_save_path)):
os.remove(results_save_path)
with open(results_save_path, "a+") as f:
f.write(results_content)
脚本效果#
效果如下,测试了补天几个专属厂商的,都能符合预期输出
台州市大数据发展中心#
浙江移动信息安全部#
使用方法:直接 python 脚本名 文件名 即可
如果有相关建议可以在评论区进行讨论