起因#
最近在生产实习,要求自己找一个网站爬一下存储数据到excel表格中
我看电影也是按豆瓣TOP250来筛选的,手动翻页太麻烦,于是爬一下
[2019-09-02 更新] 后面要做作业答辩,改为存储到mysql数据库中
代码实现#
和网上大部分爬取的文章不同,我想要的是每部电影的剧情简介信息
所以需要先获取每部电影的链接,再单独爬取每部电影
全部代码如下:
# -*- coding: utf-8 -*-
'''
@author: soapffz
@fucntion: 豆瓣TOP250电影信息爬取并存储到mysql数据库(多线程)
@time: 2019-09-01
'''
import requests
from fake_useragent import UserAgent
from lxml import etree
from tqdm import tqdm
import threading
import pymysql
from re import split
"""
提示库找不到可复制以下语句解决
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fake_useragent
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tqdm
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple threading
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pymysql
"""
class Top250(object):
def __init__(self):
ua = UserAgent() # 用于生成User-Agent
self.headers = {"User-Agent": ua.random} # 获得一个随机的User-Agent
self.bangdang_l = [] # 存储榜单的页面
self.subject_url_l = [] # 存储每部电影的链接
self.connect_mysql()
def connect_mysql(self):
# 连接数据库,密码后面可以加数据库名称
try:
self.mysql_conn = pymysql.connect(
'localhost', 'root', 'root', charset='utf8')
# 得到一个可以执行SQL语句的光标对象,执行完毕返回的结果默认以元组显示
self.cursor = self.mysql_conn.cursor()
print("数据库连接成功")
except Exception as e:
print("数据库连接出错:{}\n你让我爬完存哪?不爬了,退出程序!".format(e))
exit(0)
else:
self.create_db()
def create_db(self):
# 创建数据库和表
# 检测数据库是否存在,存在则删除,然后创建
sql_db_dection = "DROP DATABASE IF EXISTS `douban_top250`"
sql_create_db = "CREATE DATABASE `douban_top250` default charset utf8 COLLATE utf8_general_ci;"
sql_create_table = """
CREATE TABLE `movies_info` (
`电影名称` varchar(255) NOT NULL,
`导演` varchar(511) NOT NULL,
`主演信息` varchar(511) NOT NULL,
`类型` varchar(255) NOT NULL,
`上映日期` varchar(255) NOT NULL,
`剧情简介` varchar(511) NOT NULL,
`排名` varchar(255) NOT NULL,
`片长` varchar(255) NOT NULL,
PRIMARY KEY (`排名`)
)DEFAULT CHARSET=utf8;
"""
try:
self.cursor.execute(sql_db_dection)
self.cursor.execute(sql_create_db)
self.cursor.execute('use douban_top250;') # 将当前数据库设置为刚创建的数据库
self.cursor.execute(sql_create_table)
except Exception as e: # 捕获所有异常并打印,python2 是Exception,e
print("数据库创建出错:{}\n退出程序!".format(e))
self.mysql_conn.rollback() # 发生错误时回滚
self.mysql_conn.close() # 关闭数据库连接
exit(0)
else:
print("创建数据库和表成功,开始爬取每部电影的链接..")
self.get_subject_url()
def get_subject_url(self):
# 遍历250榜单获取每部电影单独链接
self.bangdang_l = [
"https://movie.douban.com/top250?start={}&filter=".format(i) for i in range(0, 250, 25)]
self.multi_thread(self.bangdang_l, self.crawl_bangdang)
if len(self.subject_url_l) == 0:
print("ip被封了,程序退出")
exit(0)
else:
print("{}部TOP电影的链接已获取完毕,开始爬取单部电影,请稍后...".format(
len(self.subject_url_l)))
self.multi_thread(self.subject_url_l, self.get_one_movie_info)
def crawl_bangdang(self, url):
# 爬取每个榜单页面的电影链接
try:
req = requests.get(url, headers=self.headers)
req.encoding = "utf-8"
html = etree.HTML(req.text)
# 获得所有a标签列表
url_l = html.xpath('//div[@class="hd"]//a/@href')
self.subject_url_l.extend(url_l)
except Exception as e:
print("爬取榜单信息时报错:{}".format(e))
else:
print("获取第{}页的榜单数据成功...\n".format(
int(int(split(r"=|&", url)[1])/25 + 1)))
def multi_thread(self, url_l, target_func):
# 多线程爬取函数,传入需要爬取的url列表以及用来爬取的函数
threads = []
for i in range(len(url_l)):
t = threading.Thread(target=target_func, args=(url_l[i],))
threads.append(t)
for i in range(len(threads)):
threads[i].start()
for i in range(len(threads)):
threads[i].join()
print("爬取完毕")
def get_one_movie_info(self, subject):
# 爬取单个url的函数
try:
req = requests.get(subject, headers=self.headers)
html = etree.HTML(req.content)
except Exception as e:
print("爬取报错:".format(e))
else:
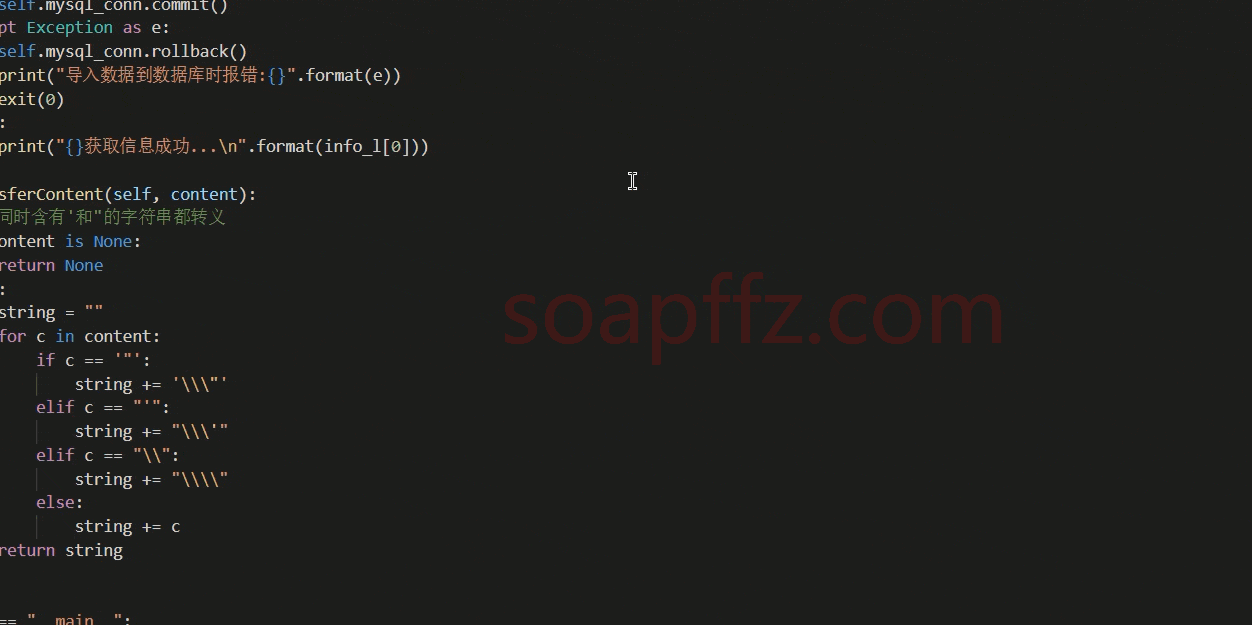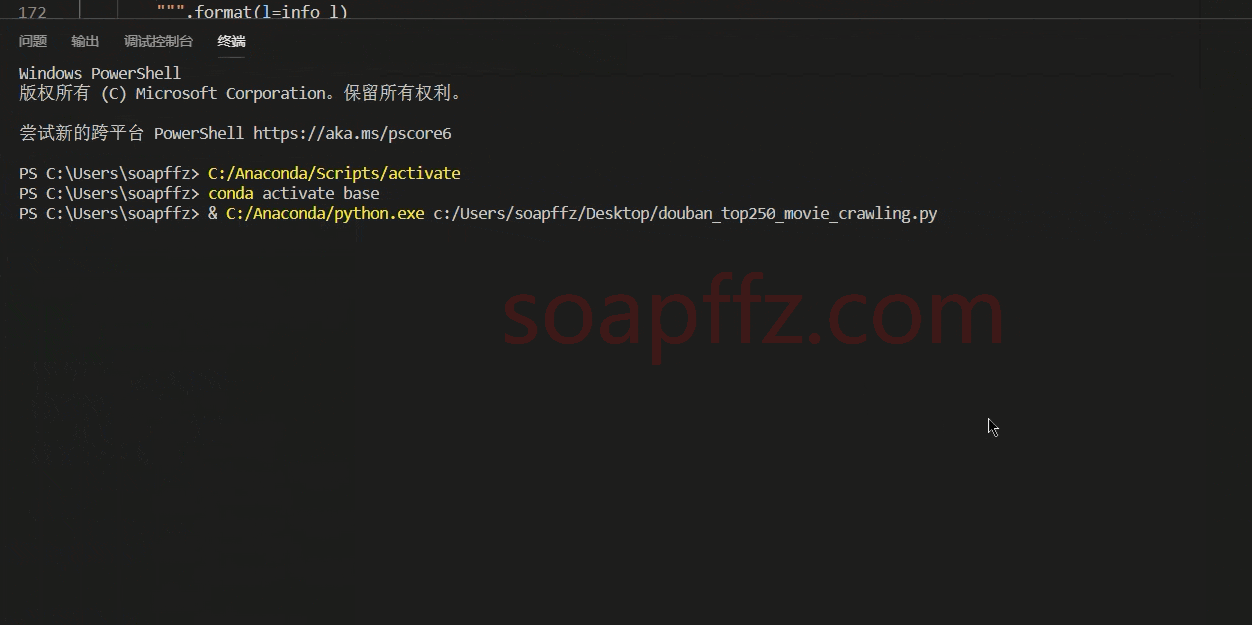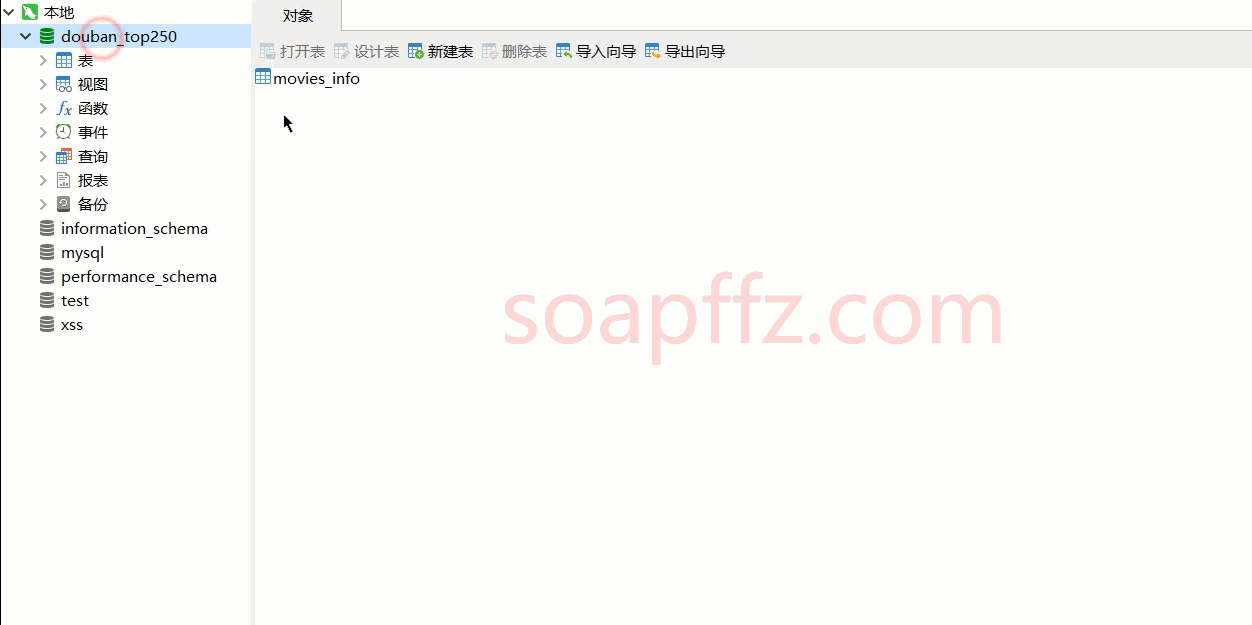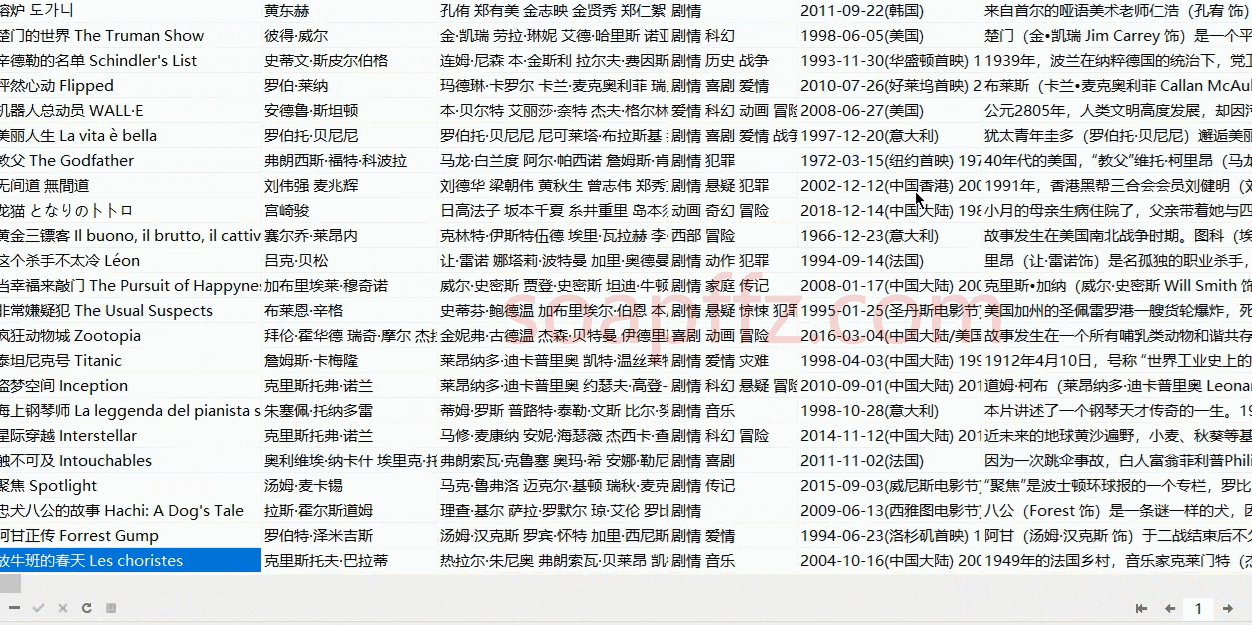
# 用来存储单个电影的信息
info = []
# 电影名称信息
movie_name = html.xpath(
"//span[@property='v:itemreviewed']/text()")
info.append(" ".join(movie_name))
# 导演信息
director = html.xpath("//a[@rel='v:directedBy']//text()")
info.append(" ".join(director))
# 主演信息
actor = html.xpath("//a[@rel='v:starring']//text()")
info.append(" ".join(actor))
# 类型
genre = html.xpath("//span[@property='v:genre']/text()")
info.append(" ".join(genre))
# 上映日期
initialReleaseDate = html.xpath(
"//span[@property='v:initialReleaseDate']/text()")
info.append(" ".join(initialReleaseDate))
# 剧情简介
reated_info = html.xpath("//span[@class='all hidden']/text()")
# 有的剧情简介是隐藏的,默认获取隐藏的标签,如果没隐藏获取没隐藏的标签
if len(reated_info) == 0:
reated_info = html.xpath(
"//span[@property='v:summary']/text()")
reated_info = "".join([s.strip() for s in reated_info]).strip("\\")
reated_info = self.transferContent(reated_info)
info.append(reated_info)
# 排名
no = html.xpath("//span[@class='top250-no']/text()")
if len(no) == 1:
info.append(no[0].split(".")[-1])
else:
info.append("获取失败")
runtime = html.xpath("//span[@property='v:runtime']/text()")
if len(runtime) == 1:
info.append(runtime[0].split("分钟")[0])
else:
info.append("获取失败")
self.db_insert(info)
def db_insert(self, info_l):
sql_insert_detection = """
insert ignore into `douban_top250`.`movies_info` (`电影名称`,`导演`,`主演信息`,`类型`,`上映日期`,`剧情简介`,`排名`,`片长`)
values ("{l[0]}","{l[1]}","{l[2]}","{l[3]}","{l[4]}","{l[5]}","{l[6]}","{l[7]}");
""".format(l=info_l)
try:
self.cursor.execute(sql_insert_detection)
self.mysql_conn.commit()
except Exception as e:
self.mysql_conn.rollback()
print("导入数据到数据库时报错:{}".format(e))
exit(0)
else:
print("{}获取信息成功...\n".format(info_l[0]))
def transferContent(self, content):
# 将同时含有'和"的字符串都转义
if content is None:
return None
else:
string = ""
for c in content:
if c == '"':
string += '\\\"'
elif c == "'":
string += "\\\'"
elif c == "\\":
string += "\\\\"
else:
string += c
return string
if __name__ == "__main__":
Top250()
演示 gif 如下:
参考文章: