事情起因#
从某公众号得到 micropoor (亮神) 大佬的渗透教程,源地址 (需翻墙):https://micropoor.blogspot.com/2019/01/php8.html
(19-02-23 更新) 亮神也在 Github 上更新着,这个是最全的,同样可以使用本文脚本重命名保持顺序:https://github.com/Micropoor/Micro8,soapffz 在 gitee 同步了这个项目,参考文章:[git clone 太慢?用码云做中转站优雅提速 (因为失败而变成了一篇水文) ]1
可直接使用:
git clone https://gitee.com/soapffz/Micro8.git
下载,看雪论坛 micropoor 大大也在更新一部分:https://www.kanxue.com/book-section_list-38.htm
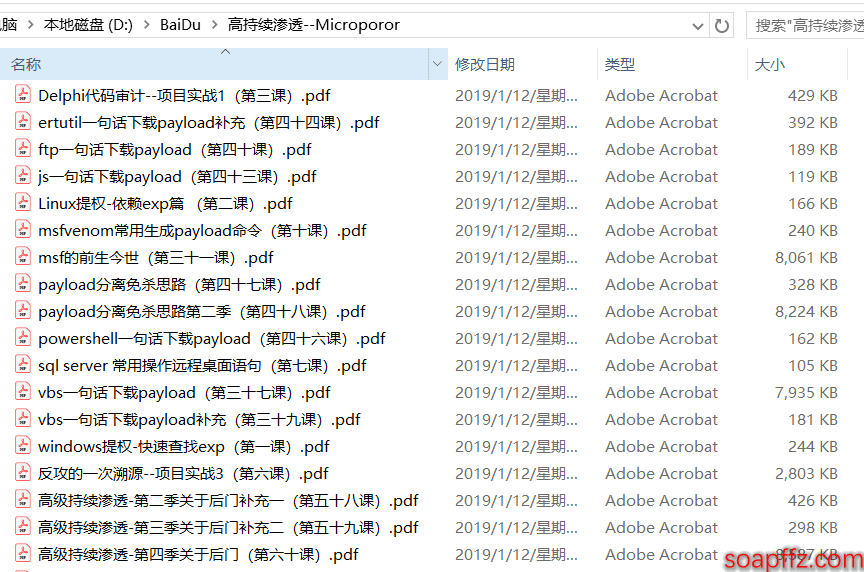
但是看到文件名的排序是 “第 xx 课” 这样的,不利于我们排序,所以我们准备把它这样批量修改:
比如将 “msf 的前生今世(第三十一课).pdf” 重命名为 “31-msf 的前生今世.pdf”
代码实现#
提取课程排序中文数字#
首先我们要把中文的第几课提取出来,用 re 正则表达式库:
import re
cc = 'msf的前生今世(第三十一课).pdf'
r1 = re.compile(u'[一二三四五六七八九十]{1,}')
print(r1.findall(cc))

可以看到已经提取出来
提取课程名字#
参考链接:https://www.cnblogs.com/lzhc/p/8744299.html
我们要把除了排序的中文数字的部分提取出来,也就是把大括号及里面的文字去掉:
import re
cc = 'msf 的前生今世(第三十一课).pdf'
a = re.sub(u"\\(.\*?)","",cc)
print(a)
输出结果:msf的前生今世.pdf
将中文数字转换为阿拉伯数字#
参考文章:https://segmentfault.com/a/1190000013048884
考虑以下几点:
1. 零在中文数字串中起补位作用,处理的时候可以忽略掉 2. 一十通常直接缩减为十,意味着十前获取不到数字时为一十 3. 单位千、百、十前的数为单个数字 4. 单位万前的数可以由(3)复合而成 5. 单位亿前的数可以由(3)、(4)及亿本身复合而成
代码实现:
digit = {'一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9}
def \_trans(s):
num = 0
if s:
idx*q, idx_b, idx_s = s.find('千'), s.find('百'), s.find('十')
if idx_q != -1:
num += digit[s[idx_q - 1:idx_q]] * 1000
if idx*b != -1:
num += digit[s[idx_b - 1:idx_b]] * 100
if idx_s != -1: # 十前忽略一的处理
num += digit.get(s[idx_s - 1:idx_s], 1) \* 10
if s[-1] in digit:
num += digit[s[-1]]
return num
def trans(chn):
chn = chn.replace('零', '')
idx*y, idx_w = chn.rfind('亿'), chn.rfind('万')
if idx_w < idx_y:
idx_w = -1
num_y, num_w = 100000000, 10000
if idx_y != -1 and idx_w != -1:
return trans(chn[:idx_y]) * num*y + \_trans(chn[idx_y + 1:idx_w]) * num*w + \_trans(chn[idx_w + 1:])
elif idx_y != -1:
return trans(chn[:idx_y]) * num*y + \_trans(chn[idx_y + 1:])
elif idx_w != -1:
return \_trans(chn[:idx_w]) * num_w + \_trans(chn[idx_w + 1:])
return \_trans(chn)
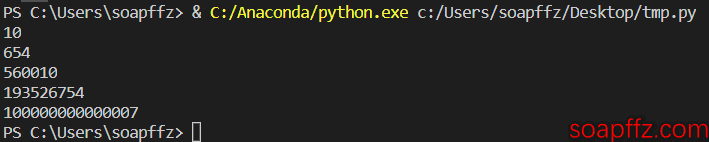
测试
print(trans('十'))
print(trans('六百五十四'))
print(trans('五十六万零一十'))
print(trans('一亿九千三百五十二万六千七百五十四'))
print(trans('一百万亿零七'))
代码汇总#
参考文章:https://www.cnblogs.com/kba977/p/3533367.html
# !/usr/bin/python
# - _ - coding:utf-8 - _ -
'''
@author: soapffz
@fucntion: 转换文件名中的中文数字为阿拉伯数字
@Description: 比如将“msf 的前生今世(第三十一课).pdf”重命名为“31-msf 的前生今世.pdf”
@time: 2019-02-06
'''
import os
import re
digit = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9}
def \_trans(s):
num = 0
if s:
idx*q, idx_b, idx_s = s.find('千'), s.find('百'), s.find('十')
if idx_q != -1:
num += digit[s[idx_q - 1:idx_q]] * 1000
if idx*b != -1:
num += digit[s[idx_b - 1:idx_b]] * 100
if idx_s != -1:
num += digit.get(s[idx_s - 1:idx_s], 1) \* 10
if s[-1] in digit:
num += digit[s[-1]]
return num
def trans(chn):
chn = chn.replace('零', '')
idx*y, idx_w = chn.rfind('亿'), chn.rfind('万')
if idx_w < idx_y:
idx_w = -1
num_y, num_w = 100000000, 10000
if idx_y != -1 and idx_w != -1:
return trans(chn[:idx_y]) * num*y + \_trans(chn[idx_y + 1:idx_w]) * num*w + \_trans(chn[idx_w + 1:])
elif idx_y != -1:
return trans(chn[:idx_y]) * num*y + \_trans(chn[idx_y + 1:])
elif idx_w != -1:
return \_trans(chn[:idx_w]) * num_w + \_trans(chn[idx_w + 1:])
return \_trans(chn)
if **name** == "**main**":
for filename in os.listdir("."): # print(filename)
split = filename.split(".") # 将文件名和缀名分成俩部分
if split[1] == 'pdf':
name = re.sub(u"\\(.\*?)", "", filename) # 正则表达式分别匹配出文件名和中文排序数字
cn_number = re.compile(u'[一二三四五六七八九十]{1,}').findall(filename)[-1::]
if cn_number: # 防止有些你已经手动转换了
number = trans(cn_number[0])
new_filename = str(number) + "-" + name # print(new_filename)
os.rename(filename, new_filename)
效果如下:
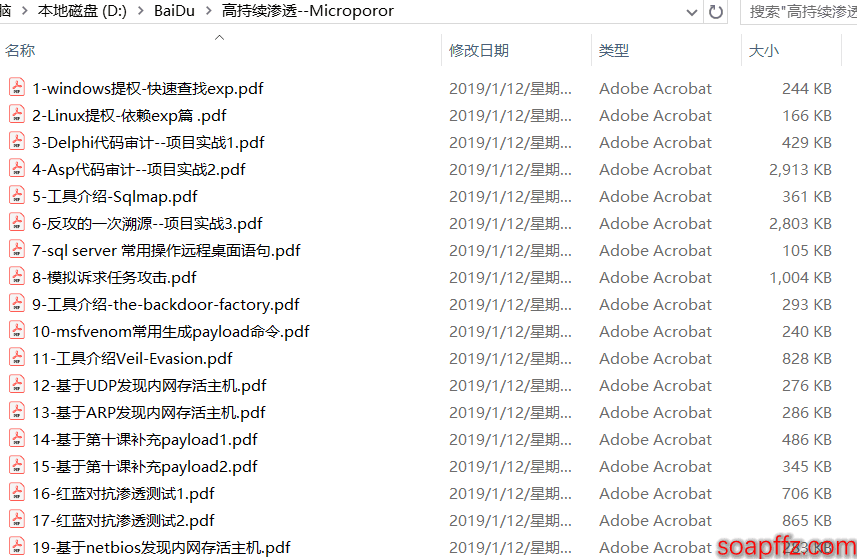
但是如果直接在 micropoor 大佬的网站上或者在 lsh4ck 的网站上下载的文件名为这样:
- 第一百课:HTTP 隧道 reDuh 第四季.pdf
- 第七十四课:基于白名单 regsvcs.exe 执行 payload 第四季.pdf
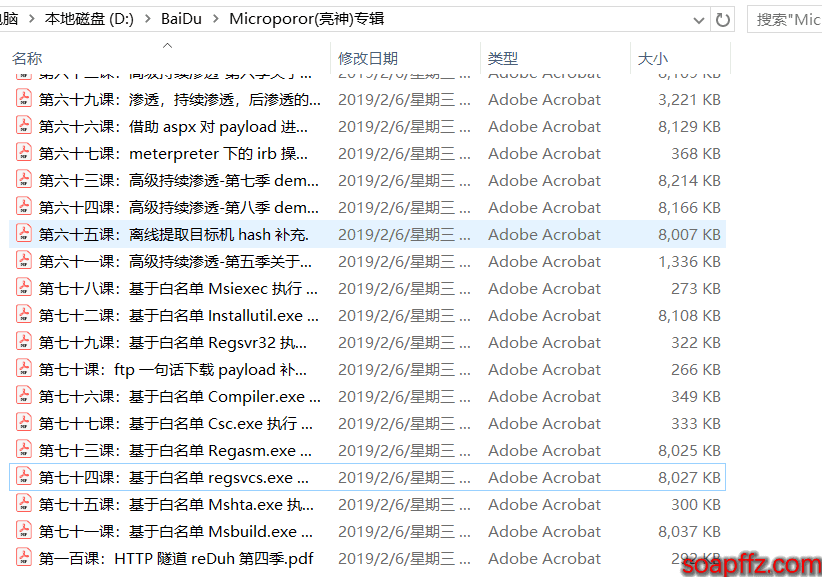
经测试,上面的代码没有考虑一百以上的中文数字,把主函数代码改为如下即可:
if **name** == "**main**":
for filename in os.listdir("."): # print(filename)
portion = os.path.splitext(filename)
if portion[1] == '.pdf':
name = re.split(':', portion[0])[1]
cn_number = re.compile(
u'[一二三四五六七八九十零百千万亿]{2,}').findall(portion[0])[0]
if cn_number:
number = trans(cn_number)
new_filename = str(number) + "-" + (name) + ".pdf" # print(new_filename)
os.rename(filename, new_filename)
自己可以对比下,只修改了一点点地方,效果如下:
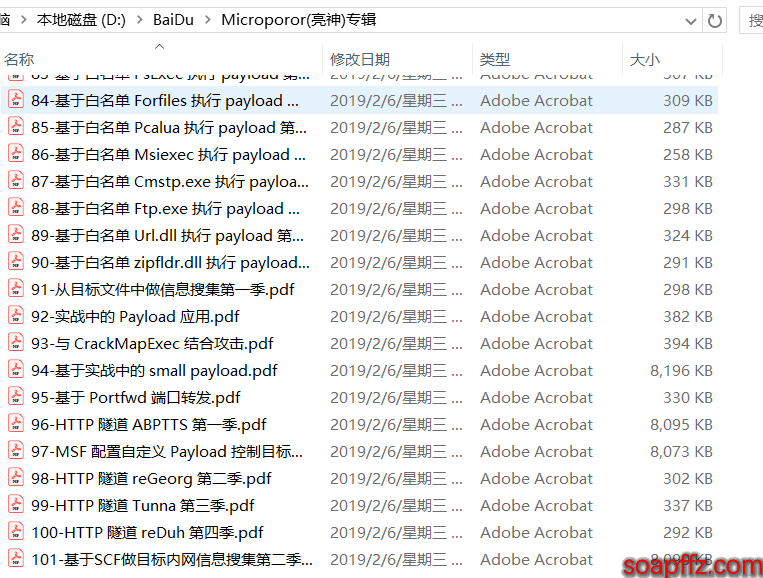
不要把已经修改完的文件与未修改的放在一起执行脚本