事の発端#
ある公式アカウントから micropoor(亮神)大佬の浸透チュートリアルを得ました。ソースアドレス(VPN が必要):https://micropoor.blogspot.com/2019/01/php8.html
(19-02-23 更新)亮神も Github で更新しています。これは最も完全なもので、同様にこの記事のスクリプトを使用して順序を保ちながらリネームできます:https://github.com/Micropoor/Micro8、soapffz が gitee でこのプロジェクトを同期しました。参考記事:[git clone が遅い?コード云で中継ステーションを使って優雅にスピードアップ(失敗したために水文になった)]1
直接使用できます:
git clone https://gitee.com/soapffz/Micro8.git
ダウンロードし、看雪フォーラムの micropoor 大大も一部を更新しています:https://www.kanxue.com/book-section_list-38.htm
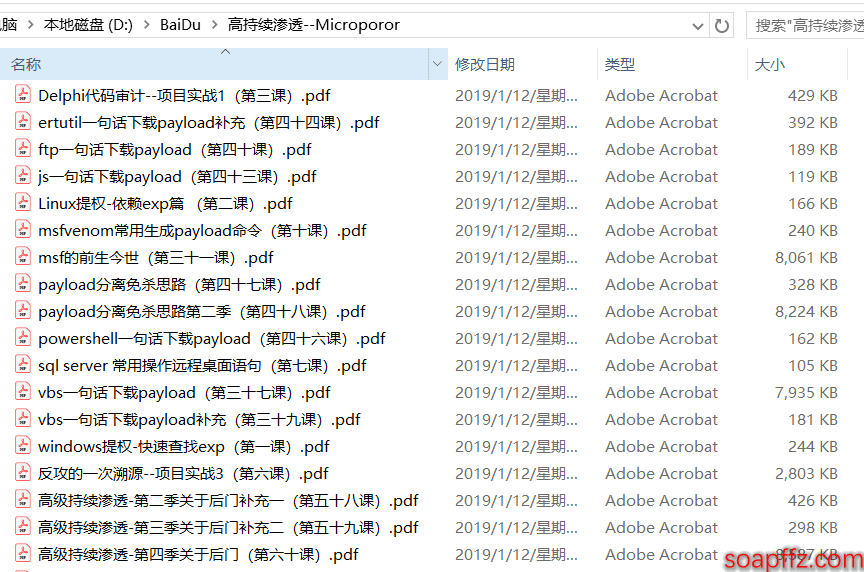
しかし、ファイル名の順序が「第 xx 課」のようになっていて、私たちの順序付けには不利なので、私たちはそれをこのように一括修正することを準備しています:
例えば、「msf の前生今世(第三十一課).pdf」を「31-msf の前生今世.pdf」にリネームします。
コード実装#
課の順序の中国語数字を抽出#
まず、中国語の第何課を抽出する必要があります。re 正規表現ライブラリを使用します:
import re
cc = 'msfの前生今世(第三十一課).pdf'
r1 = re.compile(u'[一二三四五六七八九十]{1,}')
print(r1.findall(cc))

すでに抽出できたことがわかります。
課の名前を抽出#
参考リンク:https://www.cnblogs.com/lzhc/p/8744299.html
順序の中国語数字以外の部分を抽出する必要があります。つまり、大括弧とその中の文字を取り除きます:
import re
cc = 'msfの前生今世(第三十一課).pdf'
a = re.sub(u"\\(.\*?)","",cc)
print(a)
出力結果:msfの前生今世.pdf
中国語数字をアラビア数字に変換#
参考記事:https://segmentfault.com/a/1190000013048884
以下の点を考慮します:
- 零は中国語数字列で補位の役割を果たし、処理時には無視できます。 2. 一十は通常直接十に縮小され、十の前に数字が取得できない場合は一十を意味します。 3. 単位千、百、十の前の数は単一の数字です。 4. 単位万の前の数は(3)から複合されることがあります。 5. 単位億の前の数は(3)、(4)および億自体から複合されることがあります。
コード実装:
digit = {'一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9}
def _trans(s):
num = 0
if s:
idx_q, idx_b, idx_s = s.find('千'), s.find('百'), s.find('十')
if idx_q != -1:
num += digit[s[idx_q - 1:idx_q]] * 1000
if idx_b != -1:
num += digit[s[idx_b - 1:idx_b]] * 100
if idx_s != -1: # 十の前の一の処理を無視
num += digit.get(s[idx_s - 1:idx_s], 1) * 10
if s[-1] in digit:
num += digit[s[-1]]
return num
def trans(chn):
chn = chn.replace('零', '')
idx_y, idx_w = chn.rfind('亿'), chn.rfind('万')
if idx_w < idx_y:
idx_w = -1
num_y, num_w = 100000000, 10000
if idx_y != -1 and idx_w != -1:
return trans(chn[:idx_y]) * num_y + _trans(chn[idx_y + 1:idx_w]) * num_w + _trans(chn[idx_w + 1:])
elif idx_y != -1:
return trans(chn[:idx_y]) * num_y + _trans(chn[idx_y + 1:])
elif idx_w != -1:
return _trans(chn[:idx_w]) * num_w + _trans(chn[idx_w + 1:])
return _trans(chn)
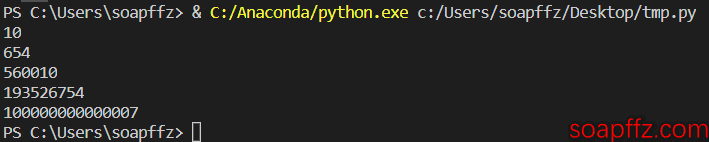
テスト
print(trans('十'))
print(trans('六百五十四'))
print(trans('五十六万零一十'))
print(trans('一亿九千三百五十二万六千七百五十四'))
print(trans('一百万亿零七'))
コードまとめ#
参考記事:https://www.cnblogs.com/kba977/p/3533367.html
# !/usr/bin/python
# - _ - coding:utf-8 - _ -
'''
@author: soapffz
@function: ファイル名の中国語数字をアラビア数字に変換する
@Description: 例えば「msfの前生今世(第三十一課).pdf」を「31-msfの前生今世.pdf」にリネームします。
@time: 2019-02-06
'''
import os
import re
digit = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9}
def _trans(s):
num = 0
if s:
idx_q, idx_b, idx_s = s.find('千'), s.find('百'), s.find('十')
if idx_q != -1:
num += digit[s[idx_q - 1:idx_q]] * 1000
if idx_b != -1:
num += digit[s[idx_b - 1:idx_b]] * 100
if idx_s != -1:
num += digit.get(s[idx_s - 1:idx_s], 1) * 10
if s[-1] in digit:
num += digit[s[-1]]
return num
def trans(chn):
chn = chn.replace('零', '')
idx_y, idx_w = chn.rfind('亿'), chn.rfind('万')
if idx_w < idx_y:
idx_w = -1
num_y, num_w = 100000000, 10000
if idx_y != -1 and idx_w != -1:
return trans(chn[:idx_y]) * num_y + _trans(chn[idx_y + 1:idx_w]) * num_w + _trans(chn[idx_w + 1:])
elif idx_y != -1:
return trans(chn[:idx_y]) * num_y + _trans(chn[idx_y + 1:])
elif idx_w != -1:
return _trans(chn[:idx_w]) * num_w + _trans(chn[idx_w + 1:])
return _trans(chn)
if __name__ == "__main__":
for filename in os.listdir("."): # print(filename)
split = filename.split(".") # ファイル名と拡張子を2つの部分に分ける
if split[1] == 'pdf':
name = re.sub(u"\\(.\*?)", "", filename) # 正規表現でファイル名と中国語の順序数字をそれぞれマッチさせる
cn_number = re.compile(u'[一二三四五六七八九十]{1,}').findall(filename)[-1::]
if cn_number: # すでに手動で変換した場合を防ぐ
number = trans(cn_number[0])
new_filename = str(number) + "-" + name # print(new_filename)
os.rename(filename, new_filename)
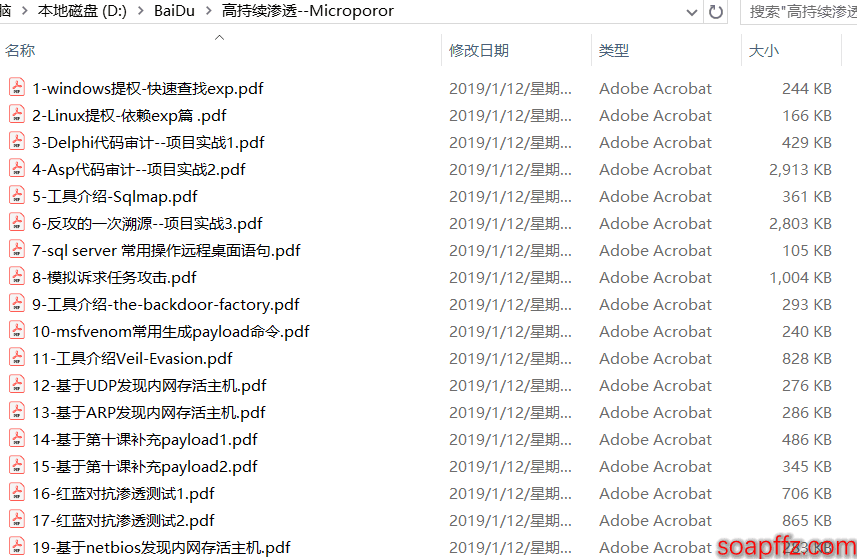
効果は以下の通り:
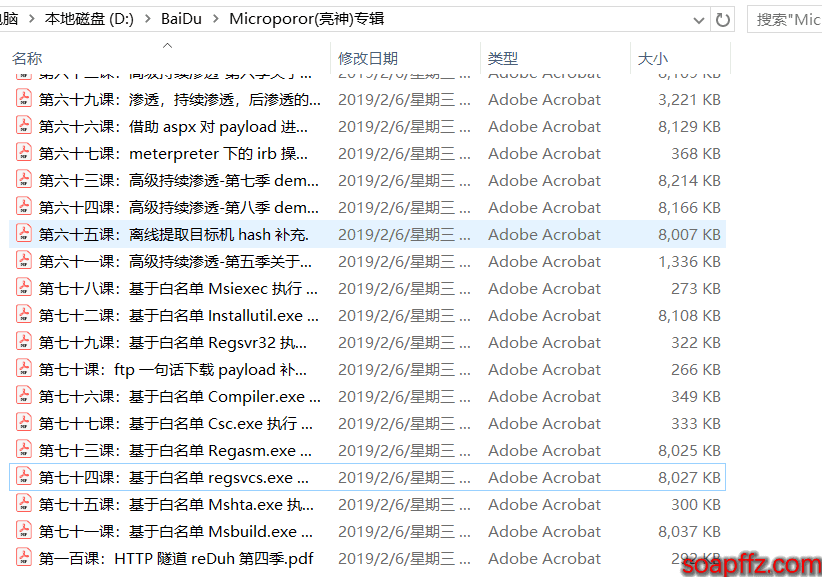
しかし、もし micropoor 大佬のウェブサイトや lsh4ck のウェブサイトから直接ダウンロードしたファイル名が以下のような場合:
- 第一百課:HTTP 隧道 reDuh 第四季.pdf
- 第七十四課:基于白名单 regsvcs.exe 执行 payload 第四季.pdf
テストの結果、上記のコードは一百以上の中国語数字を考慮していないため、メイン関数のコードを以下のように変更すれば良いです:
if __name__ == "__main__":
for filename in os.listdir("."): # print(filename)
portion = os.path.splitext(filename)
if portion[1] == '.pdf':
name = re.split(':', portion[0])[1]
cn_number = re.compile(
u'[一二三四五六七八九十零百千万亿]{2,}').findall(portion[0])[0]
if cn_number:
number = trans(cn_number)
new_filename = str(number) + "-" + (name) + ".pdf" # print(new_filename)
os.rename(filename, new_filename)
自分で比較してみてください。ほんの少しだけ変更しただけで、効果は以下の通り:
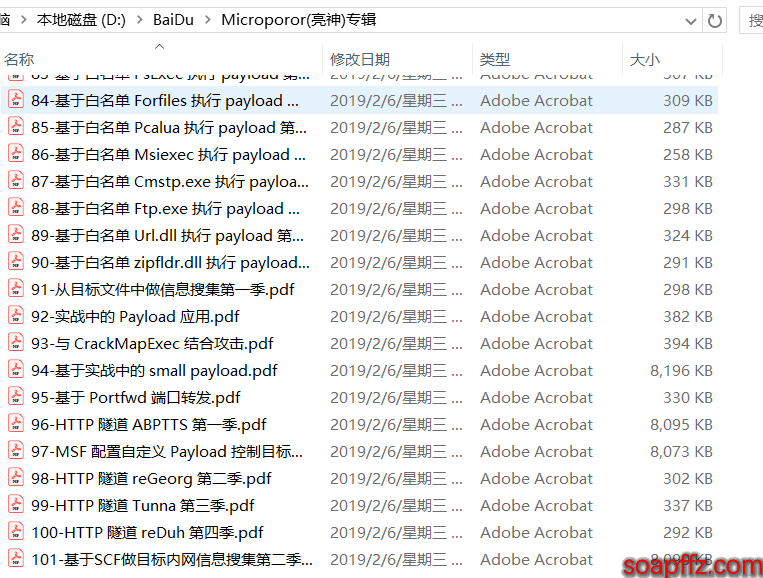
すでに修正されたファイルと未修正のファイルを一緒にスクリプトを実行しないでください