本文动力来源
1.https://mp.weixin.qq.com/s/Pim3yYbDswob8CkSGIZ49g 2.https://mp.weixin.qq.com/s/XJ-CP0wiXaJciRgEWKzATg
pkuseg 是啥?#
pkuseg 是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。
pkuseg 具有如下几个特点:
1. 高分词准确率。相比于其他的分词工具包,我们的工具包在不同领域的数据上都大幅提高了分词的准确度。根据我们的测试结果,pkuseg 分别在示例数据集(MSRA 和 CTB8)上降低了 79.33% 和 63.67% 的分词错误率。 2. 多领域分词。我们训练了多种不同领域的分词模型。根据待分词的领域特点,用户可以自由地选择不同的模型。 3. 支持用户自训练模型。支持用户使用全新的标注数据进行训练。
Github 地址:https://github.com/lancopku/PKUSeg-python
安装:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pkuseg
我的 Anaconda 环境实测在第一次运行之后会报 numpy 这个库的错,可以用 pip3 uninstall numpy 之后重新 pip3 install numpy
更新:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U pkuseg
词云是啥?#
wordcloud 词云的安装需要 Microsoft Visual C++ 14.0 运行库的支持
不建议单独去安装一个包,建议直接安装常用运行库,网上很多,这里给一个 RPK 睿派克论坛上打包的微软常用运行库合集:https://www.lanzous.com/b143614/ (RPK 论坛的人看到请记得打广告费谢谢)
另外直接pip3 install wordcloud的话是从国外的镜像下载,速度较慢,建议下载 whl 文件下来自行安装:点我去下载
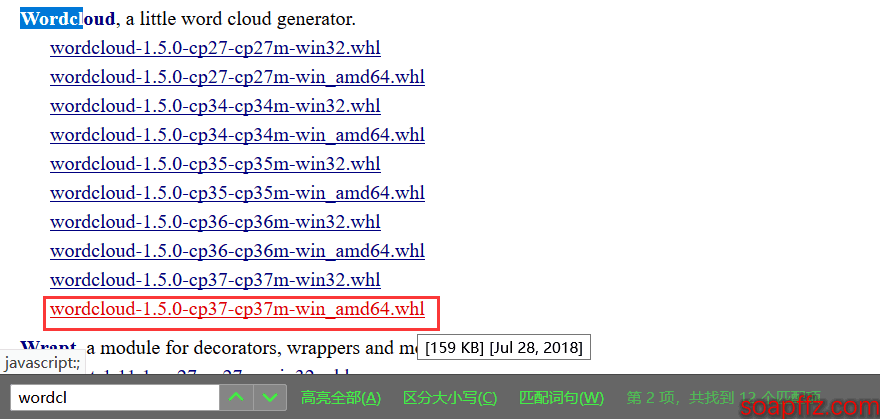
搜索 wordcloud,下载自己对应的版本,然后 pip3 install wordcloud‑1.5.0‑cp37‑cp37m‑win_amd64.whl 即可
词云代码实现#
本文所有代码及示例文件都打包了,下载地址在文末
我们先来一个简单的纯英文文本的词云生成例子
词云demo.py:
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
with open("Alice.txt") as f:
wordcloud = WordCloud(
background_color="white", # 背景颜色为白色
width=1000, # 画布宽度为1000,设置背景图片之后设置宽高不起作用
height=600, # 画布高度为600
margin=2 # 边框设置为2
).generate_from_text(f.read()) # 根据文本内容生成词云
# wordcloud.recolor(color_func=ImageColorGenerator(bak_pic)) # 设置词云颜色为图片的颜色
# 将生成的词云图保存在当前用户桌面,如重复生成会将之前的覆盖
plt.imshow(wordcloud) # imshow()作用:将一个image显示在二维坐标轴上
plt.axis("off") # 不显示坐标轴
plt.show() # 将image显示出来
效果展示:
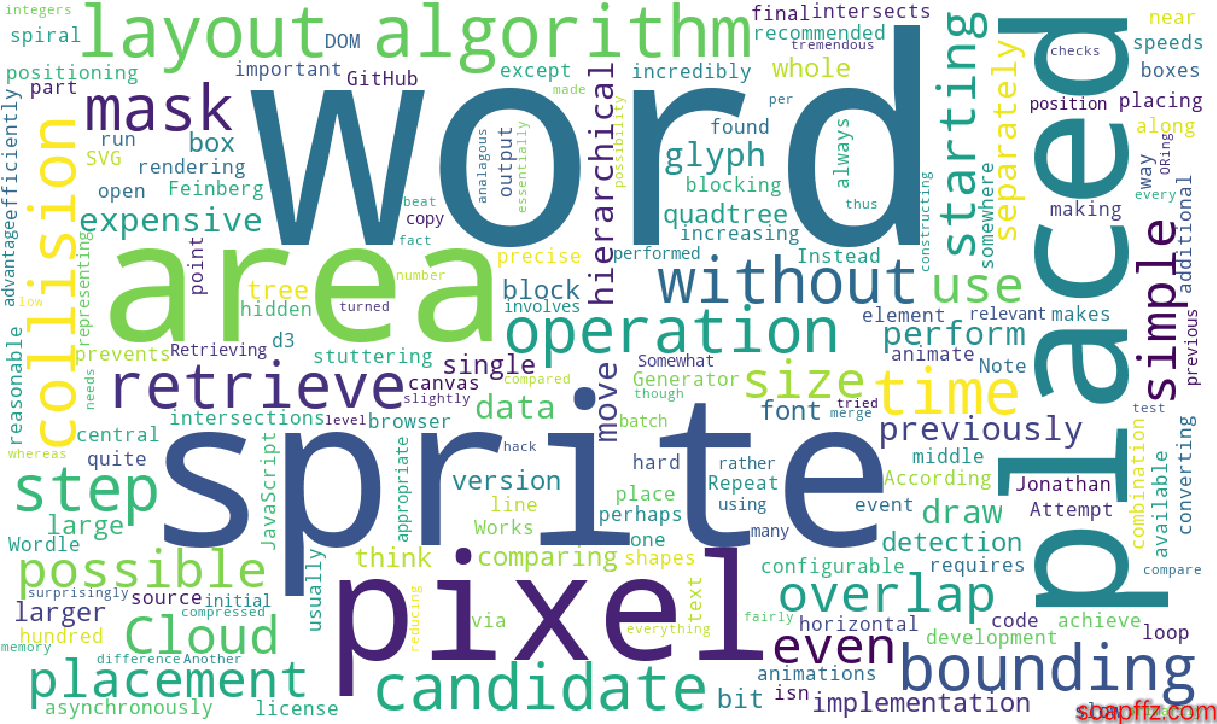
可以看到我们就已经生成了一个英文单词文本的词云图,但有如下几个新的需求:
- 需要自定义背景图片,最好能使用背景图片的颜色
- 需要对中文生成图云
- 看起来图片不咋清晰,需要清晰一点
- 需要保存每次生成的图云
第二版代码如下:
wordcloud_gen.py:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@fucntion: 使用wordcloud读取单词文本并生成词云打印出来
@time: 2019-01-31
'''
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from os import path
# 导出的词云图片的位置设置为当前用户的桌面
pic_path = path.join(path.expanduser("~")+"\\"+"Desktop"+"\\")
bak_pic = plt.imread("totoro.jpg")
with open("Alice.txt") as f:
wordcloud = WordCloud(
font_path="C:\Windows\Fonts\simsun.ttc", # 设置字体,这是win10的,win7字体后缀为ttf请自行查找
mask=bak_pic, # 设置背景图片,设置背景图片之后设置宽高不起作用
background_color="white", # 背景颜色为白色
prefer_horizontal=0.7, # 词语水平方向排版出现的频率设置为0.7(默认为0.9)
scale=15, # 画布放大倍数设置为15(默认为1)
margin=2 # 边框设置为2
).generate_from_text(f.read()) # 根据文本内容生成词云
wordcloud.recolor(color_func=ImageColorGenerator(bak_pic)) # 设置词云颜色为图片的颜色
# 将生成的词云图保存在当前用户桌面,如重复生成会将之前的覆盖
wordcloud.to_file(path.join(pic_path+"wordcloud.jpg"))
plt.imshow(wordcloud) # imshow()作用:将一个image显示在二维坐标轴上
plt.axis("off") # 不显示坐标轴
plt.show() # 将image显示出来
此处有坑 注意,上面的代码中都是直接打开文本,没有注明编码的,然后我看了一下我没报错的文本是 ANSI 编码的,也就是 win10 默认的 txt 的格式,然后我在打开一个 utf-8 编码的文本时候报了这个错误:
UnicodeDecodeError: 'gbk' codec can't decode byte 0x9d in position 809: illegal multibyte sequence
但是在with open("content.txt")时指定编码:with open("content.txt",encoding="utf-8")则可以打开 utf-8 编码的 txt,但是由于 懒 经常创建 txt,建议这里都使用 ANSI 编码,就可以不用修改代码了,如果报错的建议将 txt 另存为 ANSI 编码覆盖掉就行:
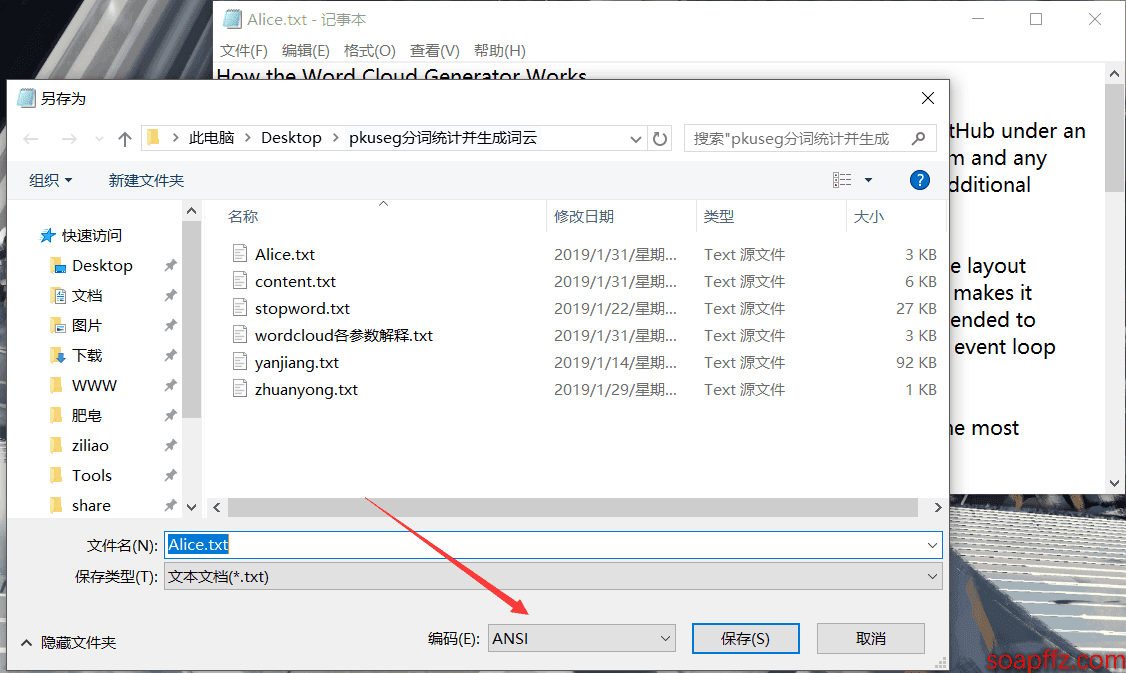
在图中右下角修改编码,并确认覆盖就行了,另外,刚打开时的右下角显示的编码即是此文本当前的编码
有这么几个参数会比较影响词云的效果:
font_path文本的字体,可以去网上自行下载,也可以使用 C:\Windows\Fonts\ 中的自带字体,注意 win10 字体后缀为 ttc,而 win7 的为 ttfbackground_color:背景色,默认黑。如果遮罩图像颜色过浅、背景设置白色,可能导致字看起来 “不清晰”。对一个浅色遮罩图分别用白、黑两种背景色后发现,黑色背景的强烈对比之下会有若干很浅也很小的词浮现出来,而之前因背景色、字色过于相近而几乎无法用肉眼看出这些词。prefer_horizontal这个参数是用来设置词语水平方向排版出现的频率的,设置的越小则在水平方向的词越多,在竖直方向上的词越少,我个人觉得默认的 0.9 太大了,建议 0.7,比较有逼格 *max_font_size:最大字号。图的生成会依据最大字号等因素去自动判断词的布局。经测试,哪怕同一个图像,只要图本身尺寸不一样(比如我把一个 300×300 的图拉大到 600×600 再去当遮罩),那么同样的字号也是会有不同的效果。原理想想也很自然,字号决定了字的尺寸,而图的尺寸变了以后,最大字相对于图的尺寸比例自然就变了。所以,需要根据期望显示的效果,去调整最大字号参数值。scale这个是画布放大倍数,数值越大,比较小的词就显示得越清楚,所以建议把这个设置为十几左右,默认的 1 会不太清晰,设置得越大耗费时间越长relative_scaling:表示词频和云词图中字大小的关系参数,默认 0.5。为 0 时,表示只考虑词排序,而不考虑词频数;为 1 时,表示两倍词频的词也会用两倍字号显示。- 另外说一下
random_state这个参数,这个是用来设置样式数量的,但是我试了一下,设置了这个参数之后不仅没有增加样式,连图片的随机样式都没有了,这个大家可以自己试一下,可能是我这的问题
其他参数可以自己添加一下试一下:
mask : nd-array or None (default=None) #如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。
font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
background_color : color value (default=”black”) #背景颜色,如background_color='white',背景颜色为白色
width : int (default=400) #输出的画布宽度,默认为400像素
height : int (default=200) #输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) #词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
min_font_size : int (default=4) #显示的最小的字体大小
max_font_size : int or None (default=None) #显示的最大的字体大小
scale : float (default=1) #按照比例进行放大画布,默认值1,如设置为1.5,则长和宽都是原来画布的1.5倍,值越大,图像密度越大越清晰
font_step : int (default=1) #字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差
max_words : number (default=200) #要显示的词的最大个数
mode : string (default=”RGB”) #当参数为“RGBA”并且background_color不为空时,背景为透明
relative_scaling : float (default=.5) #词频和字体大小的关联性
stopwords : set of strings or None #设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
color_func : callable, default=None #生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) #使用正则表达式分隔输入的文本
collocations : bool, default=True #是否包括两个词的搭配
colormap : string or matplotlib colormap, default=”viridis” #给每个单词随机分配颜色,若指定color_func,则忽略该方法
random_state : int or None #为每个单词返回一个PIL颜色
fit_words(frequencies) #根据词频生成词云
generate(text) #根据文本生成词云
generate_from_frequencies(frequencies[, ...]) #根据词频生成词云
generate_from_text(text) #根据文本生成词云
process_text(text) #将长文本分词并去除屏蔽词(此处指英语,中文分词还是需要自己用别的库先行实现,使用上面的 fit_words(frequencies) )
recolor([random_state, color_func, colormap]) #对现有输出重新着色。重新上色会比重新生成整个词云快很多
to_array() #转化为 numpy array
to_file(filename) #输出到文件
我的背景图片是龙猫:

设置与背景图片颜色相同,效果如下:
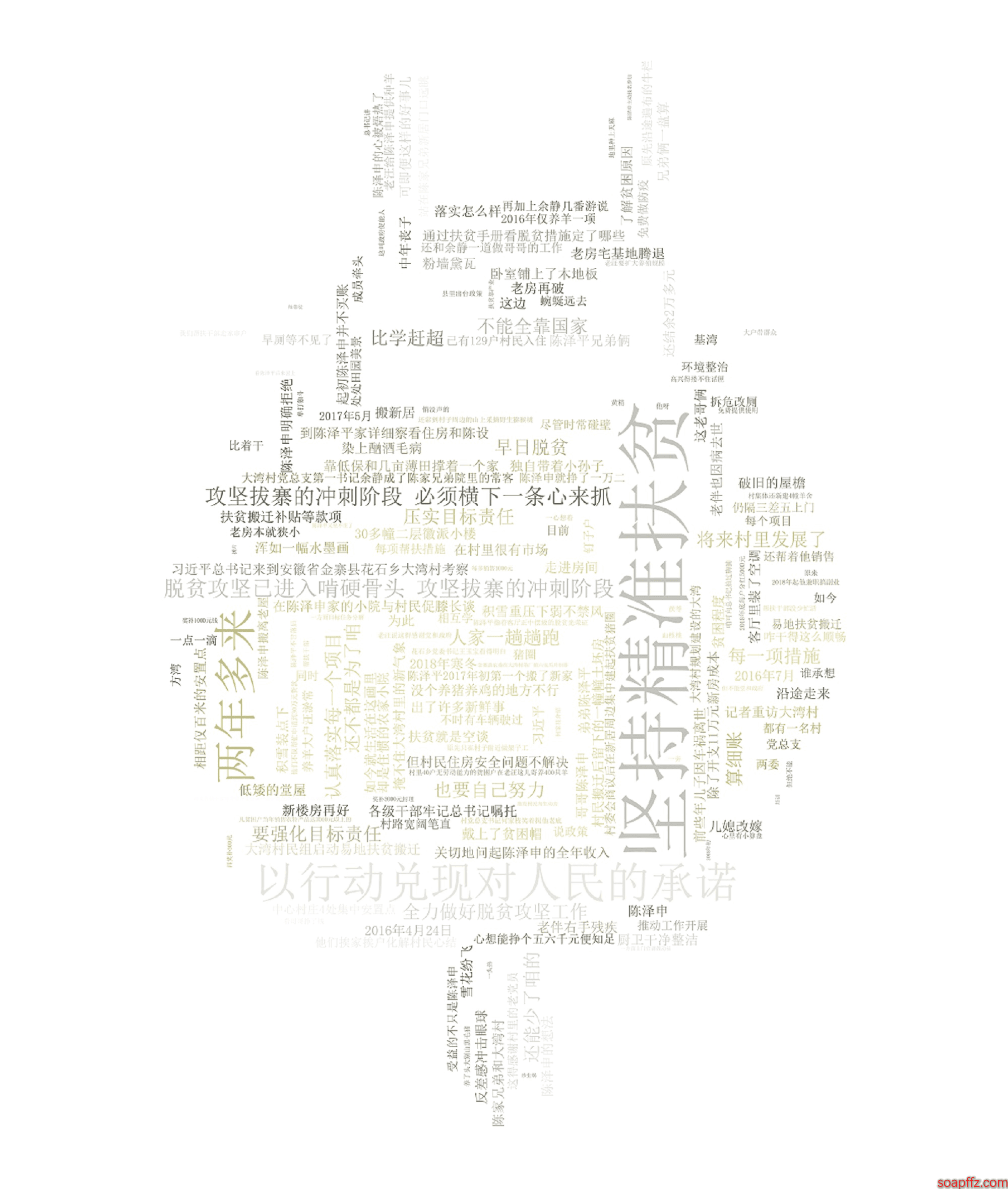
emmmm,可以看到图中的话都是一大段一大段的,这就需要靠分词来解决了
并且感觉不太好看,把设置词云颜色为图片的颜色这一行注释掉,再看看:

emmm,看来背景图片的选取很重要,最好是层次分明,且含有大片白色 ,且颜色要好看的,词云先到这里,我们来看分词
pkuseg 分词代码实现#
使用默认模型及默认词典分词
import pkuseg
seg = pkuseg.pkuseg() # 以默认配置加载模型
text = seg.cut('我爱北京天安门') # 进行分词
print(text)
输出结果:['我', '爱', '北京', '天安门']
其他的使用方式详见 GitHub 地址,我们用张小龙的 3 万字演讲做统计,步骤如下:
1. 将演讲内容下载下来,保存到一个 txt 文件中,然后将内容加载到内存 2. 用 pkuseg 对内容进行分词处理,并统计出现频率最高的前 20 个词语是哪些
import pkuseg
from collections import Counter
import pprint
content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read()
seg = pkuseg.pkuseg()
text = seg.cut(content)
counter = Counter(text)
pprint.pprint(counter.most_common(20))
输出结果:
[(',', 1441),
('的', 1278),
('。', 754),
('一个', 465),
('是', 399),
('我', 336),
('我们', 335),
('你', 229),
('了', 205),
('在', 189),
('会', 179),
('它', 170),
('微信', 164),
('有', 150),
('人', 147),
('做', 144),
('里面', 115),
('这个', 111),
('自己', 110),
('用户', 110)]
什么鬼,这都是些啥玩意,别急,其实啊,分词领域还有一个概念叫做停用词,所谓停用词就是在语境中没有具体含义的文字,例如这个、那个,你我他,的得地,以及标点符合等等。因为没人在搜索的时候去用这些没意义的停用词搜索,为了使得分词效果更好,我们就要把这些停用词过去掉,我们去网上找个停用词库。
第二版代码:
import pkuseg
from collections import Counter
import pprint
content = []
stopwords = []
new_text = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read()
seg = pkuseg.pkuseg()
text = seg.cut(content)
with open("stopword.txt", encoding="utf-8") as f:
stopwords = f.read()
for w in text:
if w not in stopwords:
new_text.append(w)
counter = Counter(new_text)
pprint.pprint(counter.most_common(20))
输出:
[('微信', 164),
('用户', 110),
('产品', 87),
('一种', 74),
('朋友圈', 72),
('程序', 55),
('社交', 55),
('这是', 43),
('视频', 41),
('希望', 39),
('游戏', 36),
('时间', 34),
('阅读', 33),
('内容', 32),
('平台', 31),
('文章', 30),
('AI', 30),
('信息', 29),
('朋友', 28),
('就像', 28)]
看起来比第一次好多了,因为停用词都过滤掉了。但是我们选出来的前 20 个高频词还是不准确,有些不应该分词的也被拆分了,例如朋友圈,公众号,小程序等词,我们认为这是一个整体。
对于这些专有名词,我们只需要指定一个用户词典, 分词时用户词典中的词固定不分开,重新进行分词:
好多公众号的教程是使用一个列表:
lexicon = ['小程序', '朋友圈', '公众号']
seg = pkuseg.pkuseg(user_dict=lexicon)
text = seg.cut(content)
我这样使用会报如下错误:
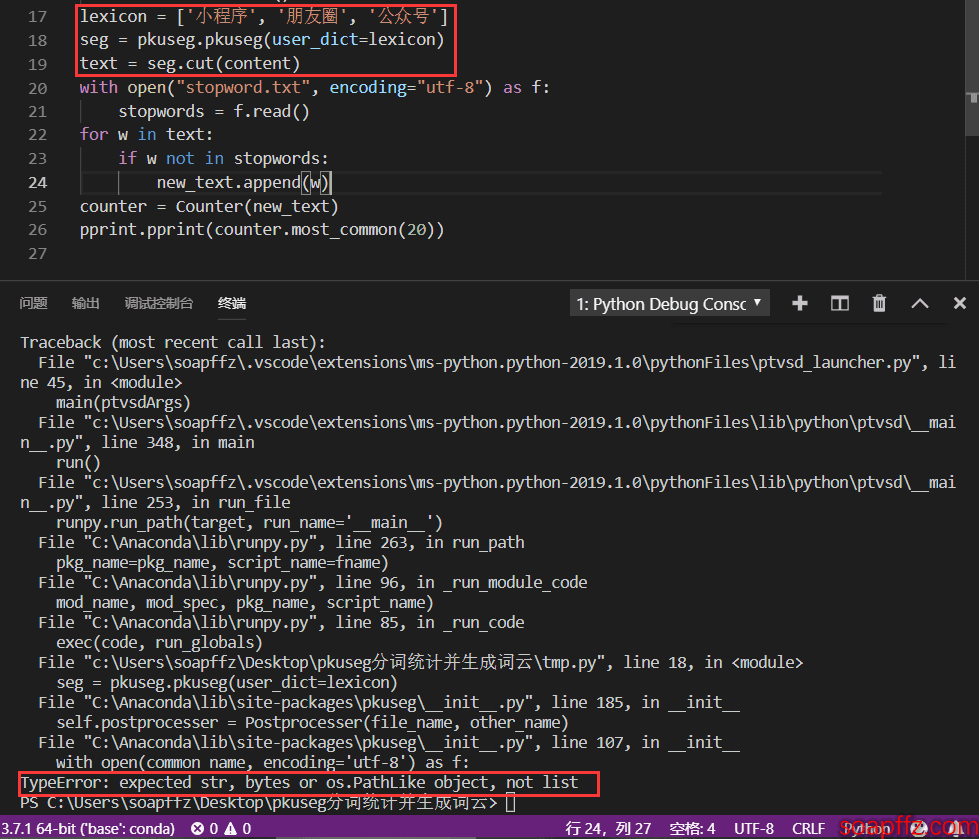
所以我这里使用官方的用法,使用自定义词典:
seg = pkuseg.pkuseg(user_dict='dict.txt') # 加载模型,给定用户词典
text = seg.cut(content)
dict.txt 中的内容为:
小程序
朋友圈
公众号
注意前面留一行,第一行的内容是读取不到的,最后出来的结果前 50 个高频词是这样的:
对张小龙演讲稿分词统计.py 输出结果:
[('微信', 164),
('用户', 110),
('产品', 89),
('朋友圈', 72),
('社交', 55),
('小程序', 53),
('视频', 41),
('希望', 39),
('时间', 38),
('游戏', 36),
('阅读', 33),
('朋友', 32),
('内容', 32),
('平台', 31),
('文章', 30),
('AI', 30),
('信息', 29),
('团队', 27),
('APP', 26),
('公众号', 25)]
可以看到张小龙讲得最多的词就是用户、朋友、原动力、价值、分享、创意、发现等这些词,这些词正是互联网的精神。
分词的程序大概就到这里了,接下来我们把分词和词云放在一起。
框架整合#
我们把上面的 wordcloud 词云代码和 pkuseg 代码合在一起,并且改用 generate_from_frequencies () 即词频统计来生成词云,代码如下:
pkuseg分词统计并生成词云.py 代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@fucntion: pkuseg分词统计并生成词云
@time: 2019-01-31
'''
import pkuseg
from collections import Counter
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from os import path
tmp_content = []
stopwords = []
with open("yanjiang.txt", encoding="utf-8") as f:
seg = pkuseg.pkuseg(user_dict='dict.txt')
text = seg.cut(f.read())
with open("stopword.txt", encoding="utf-8") as f: # 将停用词加载进来
stopwords = f.read()
for w in text:
if w not in stopwords: # 如果分词得到的词语中没有在停用词中就记录下来
tmp_content.append(w)
counter = Counter(tmp_content).most_common(30) # 得到出现频率最高的30个词语
content = {}
for i in range(len(counter)): # 将出现频率最高的30个词语及出现次数转换为字典
content[counter[i][0]] = counter[i][9]
# print(content) # 打印出分词得到的频率最高的30个词语及次数字典
# 导出的词云图片的位置设置为当前用户的桌面
pic_path = path.join(path.expanduser("~")+"\\"+"Desktop"+"\\")
bak_pic = plt.imread("totoro.jpg")
wordcloud = WordCloud(
font_path="simsun.ttc", # 设置字体,这是win10的,win7字体后缀为ttf请自行查找
mask=bak_pic, # 设置背景图片,设置背景图片之后设置宽高不起作用
background_color="white", # 背景颜色为白色
prefer_horizontal=0.7, # 词语水平方向排版出现的频率设置为0.7(默认为0.9)
scale=5, # 画布放大倍数设置为15(默认为1)
margin=2 # 边框设置为2
).generate_from_frequencies(content) # 根据词频生成词云
wordcloud.recolor(color_func=ImageColorGenerator(bak_pic)) # 设置词云颜色为图片的颜色
# 将生成的词云图保存在当前用户桌面,如重复生成会将之前的覆盖
wordcloud.to_file(path.join(pic_path+"wordcloud.jpg"))
plt.imshow(wordcloud) # imshow()作用:将一个image显示在二维坐标轴上
plt.axis("off") # 不显示坐标轴
plt.show() # 将image显示出来
效果如下:

当然这样的代码太丑了,后面有时间尽量用可视化 GUI 来创作
所有代码及示例文件下载地址:https://www.lanzous.com/i31rsdc