この記事の動機
1.https://mp.weixin.qq.com/s/Pim3yYbDswob8CkSGIZ49g 2.https://mp.weixin.qq.com/s/XJ-CP0wiXaJciRgEWKzATg
pkuseg とは?#
pkuseg は北京大学の言語計算と機械学習研究グループによって開発された新しい中国語分詞ツールキットです。
pkuseg には以下の特徴があります:
1. 高い分詞精度。他の分詞ツールキットと比較して、私たちのツールキットは異なる分野のデータにおいて分詞の精度を大幅に向上させました。私たちのテスト結果によると、pkuseg はそれぞれのサンプルデータセット(MSRA と CTB8)で 79.33% と 63.67% の分詞エラー率を低下させました。 2. 多分野の分詞。私たちはさまざまな分野の分詞モデルを訓練しました。分詞対象の分野の特徴に応じて、ユーザーは異なるモデルを自由に選択できます。 3. ユーザーによる自己訓練モデルのサポート。ユーザーは新しいアノテーションデータを使用して訓練することができます。
Github アドレス:https://github.com/lancopku/PKUSeg-python
インストール:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pkuseg
私の Anaconda 環境では、最初の実行後に numpy ライブラリのエラーが発生することがあります。pip3 uninstall numpyの後、再度pip3 install numpyを実行してください。
更新:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -U pkuseg
ワードクラウドとは?#
wordcloud のインストールには Microsoft Visual C++ 14.0 ランタイムライブラリのサポートが必要です。
単独でパッケージをインストールすることはお勧めしません。一般的なランタイムライブラリを直接インストールすることをお勧めします。ネット上には多くありますが、ここでは RPK フォーラムでパッケージ化された Microsoft の一般的なランタイムライブラリのコレクションを紹介します:https://www.lanzous.com/b143614/ (RPK フォーラムの方々、広告費を忘れずにお願いします)
また、直接pip3 install wordcloudを実行すると海外のミラーからダウンロードされるため、速度が遅くなります。whl ファイルをダウンロードして自分でインストールすることをお勧めします:ここをクリックしてダウンロード
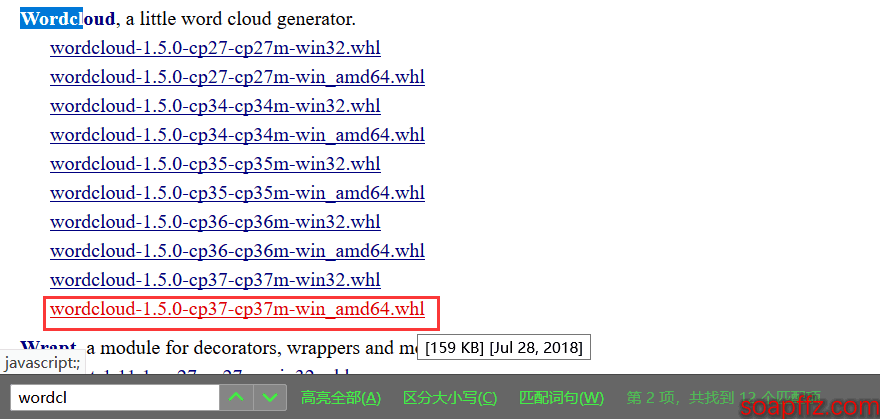
wordcloud を検索し、自分に対応するバージョンをダウンロードして、pip3 install wordcloud‑1.5.0‑cp37‑cp37m‑win_amd64.whlを実行すれば大丈夫です。
ワードクラウドのコード実装#
この記事のすべてのコードとサンプルファイルはパッケージ化されており、ダウンロードリンクは文末にあります。
まずはシンプルな英語テキストのワードクラウド生成の例を見てみましょう。
ワードクラウドdemo.py:
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
with open("Alice.txt") as f:
wordcloud = WordCloud(
background_color="white", # 背景色を白に設定
width=1000, # キャンバスの幅を1000に設定、背景画像を設定した後は幅と高さは無効
height=600, # キャンバスの高さを600に設定
margin=2 # マージンを2に設定
).generate_from_text(f.read()) # テキスト内容に基づいてワードクラウドを生成
# wordcloud.recolor(color_func=ImageColorGenerator(bak_pic)) # ワードクラウドの色を画像の色に設定
# 生成されたワードクラウド画像を現在のユーザーデスクトップに保存、再生成すると以前のものが上書きされる
plt.imshow(wordcloud) # imshow()の役割:画像を2次元座標軸に表示
plt.axis("off") # 座標軸を表示しない
plt.show() # 画像を表示
効果の展示:
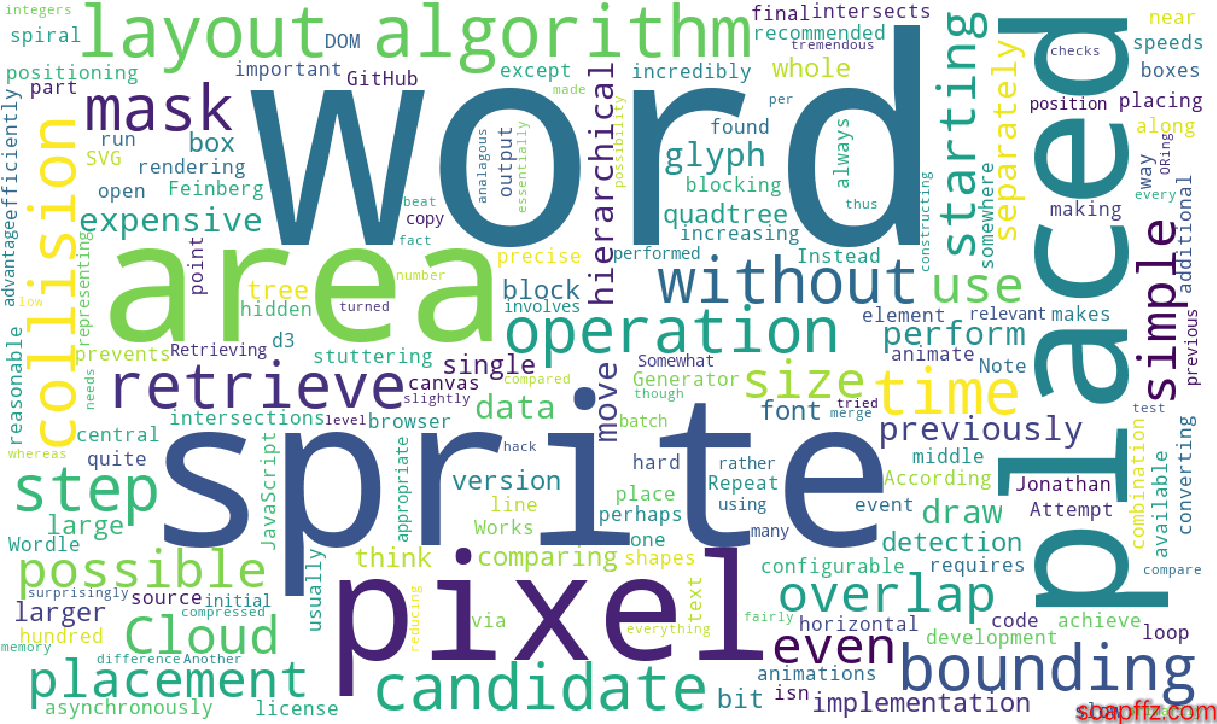
すでに英単語のテキストのワードクラウドが生成されていることがわかりますが、以下の新しい要求があります:
- 背景画像をカスタマイズしたい、できれば背景画像の色を使用したい
- 中国語のワードクラウドを生成する必要がある
- 画像があまり鮮明ではないように見えるので、もう少し鮮明にしたい
- 毎回生成したワードクラウドを保存する必要がある
第二版のコードは以下の通りです:
wordcloud_gen.py:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: wordcloudを使用して単語テキストを読み込み、ワードクラウドを生成して表示
@time: 2019-01-31
'''
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from os import path
# エクスポートするワードクラウド画像の位置を現在のユーザーのデスクトップに設定
pic_path = path.join(path.expanduser("~")+"\\"+"Desktop"+"\\")
bak_pic = plt.imread("totoro.jpg")
with open("Alice.txt") as f:
wordcloud = WordCloud(
font_path="C:\Windows\Fonts\simsun.ttc", # フォントを設定、これはwin10のもので、win7のフォント拡張子はttfですので自分で探してください
mask=bak_pic, # 背景画像を設定、背景画像を設定した後は幅と高さは無効
background_color="white", # 背景色を白に設定
prefer_horizontal=0.7, # 単語の水平方向の配置頻度を0.7に設定(デフォルトは0.9)
scale=15, # キャンバスの拡大倍率を15に設定(デフォルトは1)
margin=2 # マージンを2に設定
).generate_from_text(f.read()) # テキスト内容に基づいてワードクラウドを生成
wordcloud.recolor(color_func=ImageColorGenerator(bak_pic)) # ワードクラウドの色を画像の色に設定
# 生成されたワードクラウド画像を現在のユーザーデスクトップに保存、再生成すると以前のものが上書きされる
wordcloud.to_file(path.join(pic_path+"wordcloud.jpg"))
plt.imshow(wordcloud) # imshow()の役割:画像を2次元座標軸に表示
plt.axis("off") # 座標軸を表示しない
plt.show() # 画像を表示
ここに注意点があります 上記のコードではテキストを直接開いていますが、エンコーディングを指定していません。私が確認したところ、エラーが出なかったテキストは ANSI エンコーディングで、つまり win10 のデフォルトの txt 形式です。utf-8 エンコーディングのテキストを開こうとしたときに次のエラーが発生しました:
UnicodeDecodeError: 'gbk' codec can't decode byte 0x9d in position 809: illegal multibyte sequence
しかし、with open("content.txt", encoding="utf-8")と指定すると utf-8 エンコーディングの txt を開くことができますが、怠惰 よく txt を作成するため、ここではすべて ANSI エンコーディングを使用することをお勧めします。エラーが出た場合は、txt を別名で ANSI エンコーディングで保存し直せば大丈夫です:
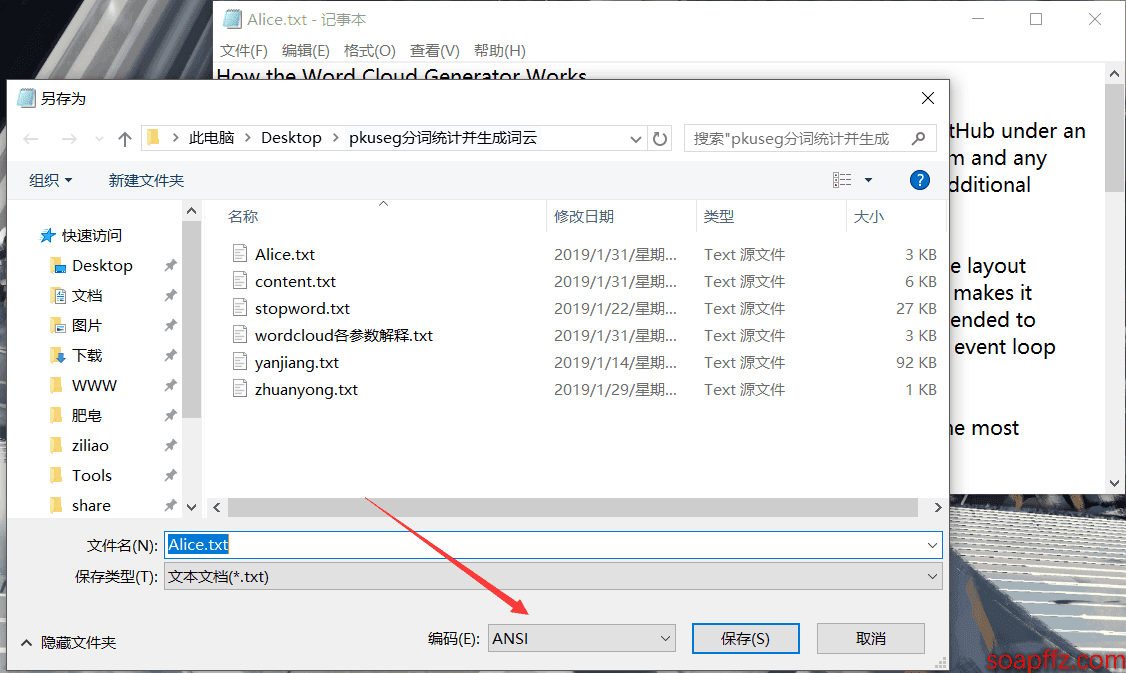
図の右下でエンコーディングを変更し、上書きすることを確認すれば大丈夫です。また、最初に開いたときの右下に表示されるエンコーディングがこのテキストの現在のエンコーディングです。
ワードクラウドの効果に影響を与えるいくつかのパラメータがあります:
font_pathテキストのフォント、ネットで自分でダウンロードすることもできますし、C:\Windows\Fonts\ にある自前のフォントを使用することもできます。win10 のフォント拡張子は ttc で、win7 のものは ttf ですので注意してください。background_color:背景色、デフォルトは黒です。マスク画像の色が薄すぎて、背景を白に設定すると、文字が「不鮮明」に見える可能性があります。薄い色のマスク画像に対して白と黒の 2 種類の背景色を使用したところ、黒い背景の強いコントラストの下で、非常に薄くて小さな単語がいくつか浮かび上がってきましたが、以前は背景色と文字色が近すぎて肉眼ではほとんど見えませんでした。prefer_horizontalこのパラメータは単語の水平方向の配置頻度を設定するためのもので、値を小さくするほど水平方向の単語が多く、垂直方向の単語が少なくなります。個人的にはデフォルトの 0.9 は大きすぎると思うので、0.7 をお勧めします。よりスタイリッシュです。 *max_font_size:最大フォントサイズ。画像の生成は最大フォントサイズなどの要素に基づいて単語のレイアウトを自動的に判断します。テストの結果、同じ画像であっても、画像のサイズが異なる(例えば 300×300 の画像を 600×600 に引き伸ばすなど)と、同じフォントサイズでも異なる効果が得られます。原理は考えれば自然です。フォントサイズは文字のサイズを決定し、画像のサイズが変わると、最大文字は画像のサイズに対する比率が変わります。したがって、期待する表示効果に応じて最大フォントサイズのパラメータ値を調整する必要があります。scaleこれはキャンバスの拡大倍率で、数値が大きいほど小さな単語がより鮮明に表示されるため、これを 10 以上に設定することをお勧めします。デフォルトの 1 ではあまり鮮明ではなく、値を大きくすると時間がかかります。relative_scaling:単語の頻度とワードクラウド内の単語サイズの関係を示すパラメータで、デフォルトは 0.5 です。0 の場合、単語の順序のみを考慮し、単語の頻度は考慮しません。1 の場合、2 倍の頻度の単語も 2 倍のフォントサイズで表示されます。- また、
random_stateこのパラメータはスタイルの数を設定するためのもので、これを設定するとスタイルが増えるどころか、画像のランダムスタイルも失われることがあるので、これは皆さん自身で試してみてください。私の問題かもしれません。
他のパラメータも自分で追加して試してみてください:
mask : nd-array or None (default=None) #このパラメータが空の場合、2次元マスクを使用してワードクラウドを描画します。maskが空でない場合、設定した幅と高さの値は無視され、マスクの形状がmaskに置き換えられます。全白(#FFFFFF)の部分は描画されず、残りの部分はワードクラウドの描画に使用されます。例:bg_pic = imread('画像を読み込む.png')、背景画像のキャンバスは必ず白色(#FFFFFF)に設定し、表示される形状は白色でない他の色になります。表示したい形状を純白のキャンバスにコピーして保存することができます。
font_path : string #フォントパス、表示したいフォントのパス+拡張子を記述します。例:font_path = '黒体.ttf'
background_color : color value (default=”black”) #背景色、例background_color='white'、背景色は白
width : int (default=400) #出力キャンバスの幅、デフォルトは400ピクセル
height : int (default=200) #出力キャンバスの高さ、デフォルトは200ピクセル
prefer_horizontal : float (default=0.90) #単語の水平方向の配置頻度、デフォルトは0.9(したがって単語の垂直方向の配置頻度は0.1)
min_font_size : int (default=4) #表示される最小フォントサイズ
max_font_size : int or None (default=None) #表示される最大フォントサイズ
scale : float (default=1) #比率に基づいてキャンバスを拡大、デフォルト値1、1.5に設定すると、長さと幅は元のキャンバスの1.5倍になります。値が大きいほど、画像の密度が高く、鮮明になります。
font_step : int (default=1) #フォントステップ、ステップが1より大きい場合、計算が速くなりますが、結果に大きな誤差が生じる可能性があります。
max_words : number (default=200) #表示する単語の最大数
mode : string (default=”RGB”) #パラメータが“RGBA”でbackground_colorが空でない場合、背景は透明になります。
relative_scaling : float (default=.5) #単語頻度とフォントサイズの関連性
stopwords : set of strings or None #除外する単語を設定します。空の場合、組み込みのSTOPWORDSを使用します。
color_func : callable, default=None #新しい色を生成する関数。空の場合、self.color_funcを使用します。
regexp : string or None (optional) #正規表現を使用して入力テキストを分割します。
collocations : bool, default=True #2つの単語の組み合わせを含めるかどうか
colormap : string or matplotlib colormap, default=”viridis” #各単語にランダムに色を割り当てます。color_funcを指定した場合、この方法は無視されます。
random_state : int or None #各単語にPIL色を返します。
fit_words(frequencies) #単語頻度に基づいてワードクラウドを生成
generate(text) #テキストに基づいてワードクラウドを生成
generate_from_frequencies(frequencies[, ...]) #単語頻度に基づいてワードクラウドを生成
generate_from_text(text) #テキストに基づいてワードクラウドを生成
process_text(text) #長いテキストを分詞し、除外単語を削除します(ここでは英語を指し、中国語の分詞は別のライブラリを使用して実装する必要があります。上記のfit_words(frequencies)を使用します)
recolor([random_state, color_func, colormap]) #既存の出力を再着色します。再着色はワードクラウド全体を再生成するよりもはるかに速いです。
to_array() #numpy配列に変換
to_file(filename) #ファイルに出力
私の背景画像はトトロです:

背景画像の色と同じに設定した場合、効果は以下の通りです:
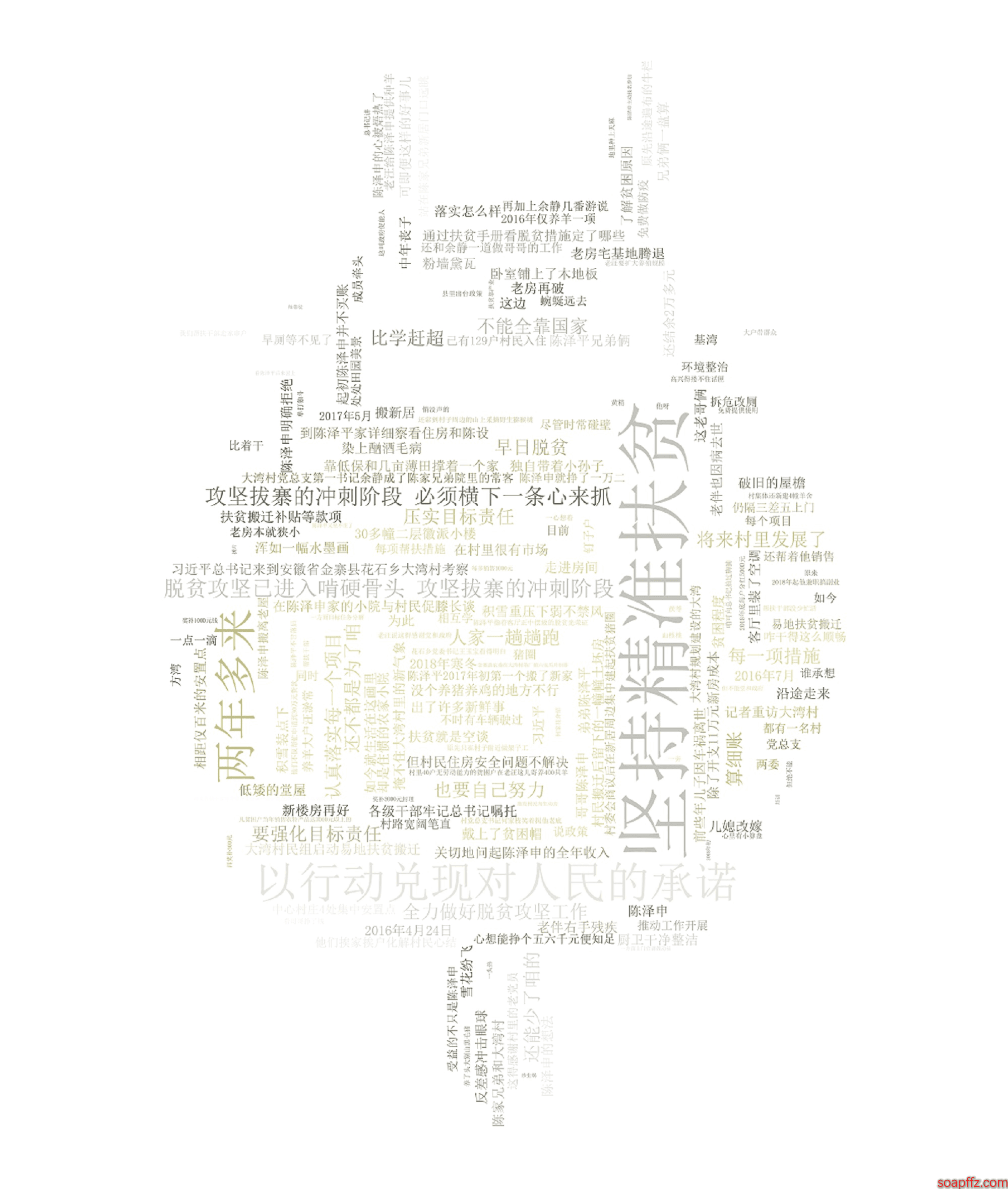
emmmm、図の中の言葉が一大段落になっていることがわかります。これは分詞によって解決する必要があります。
また、あまり見栄えが良くないように感じるので、ワードクラウドの色を画像の色に設定する行をコメントアウトして、もう一度見てみましょう:

emmm、背景画像の選択が非常に重要であることがわかります。できれば層がはっきりしていて、大きな白色部分があり、色が美しいものが望ましいです。ワードクラウドはここまでにして、分詞を見てみましょう。
pkuseg 分詞コード実装#
デフォルトモデルとデフォルト辞書を使用して分詞します。
import pkuseg
seg = pkuseg.pkuseg() # デフォルト設定でモデルを読み込む
text = seg.cut('私は北京天安門を愛しています') # 分詞を実行
print(text)
出力結果:['私', 'は', '北京', '天安門', 'を', '愛して', 'います']
他の使用方法については GitHub アドレスを参照してください。私たちは張小龍の 3 万字のスピーチを統計します。手順は以下の通りです:
1. スピーチ内容をダウンロードし、txt ファイルに保存し、内容をメモリに読み込む 2.pkuseg を使用して内容を分詞処理し、出現頻度が最も高い上位 20 の単語を統計します。
import pkuseg
from collections import Counter
import pprint
content = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read()
seg = pkuseg.pkuseg()
text = seg.cut(content)
counter = Counter(text)
pprint.pprint(counter.most_common(20))
出力結果:
[('、', 1441),
('の', 1278),
('。', 754),
('一つ', 465),
('は', 399),
('私', 336),
('私たち', 335),
('あなた', 229),
('了', 205),
('で', 189),
('会', 179),
('それ', 170),
('WeChat', 164),
('ある', 150),
('人', 147),
('する', 144),
('中', 115),
('この', 111),
('自分', 110),
('ユーザー', 110)]
何ですか、これは何の意味もないものです。心配しないでください。実は、分詞の分野にはストップワードという概念があります。ストップワードとは、文脈の中で具体的な意味を持たない文字のことです。例えば、この、その、あなた、私、の、得、地、そして句読点などです。誰も検索するときにこれらの意味のないストップワードを使って検索することはないので、分詞の効果を向上させるために、これらのストップワードを取り除く必要があります。ネットでストップワードのライブラリを探してみましょう。
第二版のコード:
import pkuseg
from collections import Counter
import pprint
content = []
stopwords = []
new_text = []
with open("yanjiang.txt", encoding="utf-8") as f:
content = f.read()
seg = pkuseg.pkuseg()
text = seg.cut(content)
with open("stopword.txt", encoding="utf-8") as f:
stopwords = f.read()
for w in text:
if w not in stopwords:
new_text.append(w)
counter = Counter(new_text)
pprint.pprint(counter.most_common(20))
出力:
[('WeChat', 164),
('ユーザー', 110),
('製品', 87),
('一種', 74),
('友達のサークル', 72),
('プログラム', 55),
('ソーシャル', 55),
('これは', 43),
('動画', 41),
('希望', 39),
('ゲーム', 36),
('時間', 34),
('読書', 33),
('内容', 32),
('プラットフォーム', 31),
('記事', 30),
('AI', 30),
('情報', 29),
('友達', 28),
('ちょうど', 28)]
見たところ、前回よりもずっと良くなりました。ストップワードがすべてフィルタリングされました。しかし、選ばれた上位 20 の高頻度単語はまだ正確ではありません。分詞すべきでないものも分割されてしまいました。例えば、友達のサークル、公式アカウント、小プログラムなどの単語は、私たちにとって一つのまとまりです。
これらの固有名詞については、ユーザー辞書を指定するだけで、分詞時にユーザー辞書内の単語を固定して分割しないようにします。再度分詞を行います:
多くの公式アカウントのチュートリアルではリストを使用しています:
lexicon = ['小プログラム', '友達のサークル', '公式アカウント']
seg = pkuseg.pkuseg(user_dict=lexicon)
text = seg.cut(content)
このように使用すると、次のエラーが発生します:
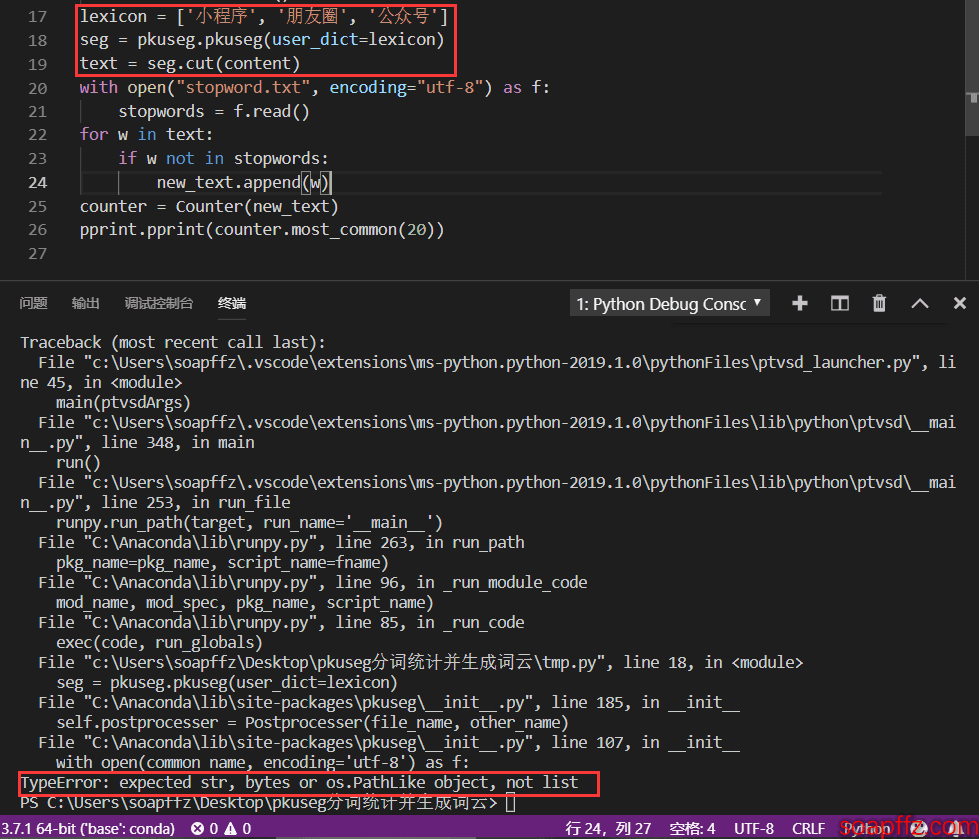
したがって、ここでは公式の使い方を使用して、カスタム辞書を使用します:
seg = pkuseg.pkuseg(user_dict='dict.txt') # モデルを読み込み、ユーザー辞書を指定
text = seg.cut(content)
dict.txt の内容は:
小プログラム
友達のサークル
公式アカウント
最初の行には空白を残すことに注意してください。最初の行の内容は読み取れません。最終的に得られた結果の上位 50 の高頻度単語は次の通りです:
張小龍のスピーチ原稿分詞統計.py 出力結果:
[('WeChat', 164),
('ユーザー', 110),
('製品', 89),
('友達のサークル', 72),
('ソーシャル', 55),
('小プログラム', 53),
('動画', 41),
('希望', 39),
('時間', 38),
('ゲーム', 36),
('読書', 33),
('友達', 32),
('内容', 32),
('プラットフォーム', 31),
('記事', 30),
('AI', 30),
('情報', 29),
('チーム', 27),
('アプリ', 26),
('公式アカウント', 25)]
張小龍が最も多く話した単語はユーザー、友達、原動力、価値、共有、創造、発見などであり、これらの単語はインターネットの精神そのものです。
分詞のプログラムはここまでです。次に、分詞とワードクラウドを組み合わせます。
フレームワーク統合#
上記のワードクラウドのコードと pkuseg のコードを統合し、generate_from_frequencies () を使用してワードクラウドを生成するための単語頻度統計を行います。コードは以下の通りです:
pkuseg分詞統計とワードクラウド生成.py コード:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@function: pkuseg分詞統計とワードクラウド生成
@time: 2019-01-31
'''
import pkuseg
from collections import Counter
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from os import path
tmp_content = []
stopwords = []
with open("yanjiang.txt", encoding="utf-8") as f:
seg = pkuseg.pkuseg(user_dict='dict.txt')
text = seg.cut(f.read())
with open("stopword.txt", encoding="utf-8") as f: # ストップワードを読み込む
stopwords = f.read()
for w in text:
if w not in stopwords: # 分詞結果の単語がストップワードに含まれていない場合、記録する
tmp_content.append(w)
counter = Counter(tmp_content).most_common(30) # 最も頻繁に出現する30の単語を取得
content = {}
for i in range(len(counter)): # 最も頻繁に出現する30の単語と出現回数を辞書に変換
content[counter[i][0]] = counter[i][9]
# print(content) # 分詞結果の頻度が最も高い30の単語とその出現回数の辞書を表示
# エクスポートするワードクラウド画像の位置を現在のユーザーのデスクトップに設定
pic_path = path.join(path.expanduser("~")+"\\"+"Desktop"+"\\")
bak_pic = plt.imread("totoro.jpg")
wordcloud = WordCloud(
font_path="simsun.ttc", # フォントを設定、これはwin10のもので、win7のフォント拡張子はttfですので自分で探してください
mask=bak_pic, # 背景画像を設定、背景画像を設定した後は幅と高さは無効
background_color="white", # 背景色を白に設定
prefer_horizontal=0.7, # 単語の水平方向の配置頻度を0.7に設定(デフォルトは0.9)
scale=5, # キャンバスの拡大倍率を15に設定(デフォルトは1)
margin=2 # マージンを2に設定
).generate_from_frequencies(content) # 単語頻度に基づいてワードクラウドを生成
wordcloud.recolor(color_func=ImageColorGenerator(bak_pic)) # ワードクラウドの色を画像の色に設定
# 生成されたワードクラウド画像を現在のユーザーデスクトップに保存、再生成すると以前のものが上書きされる
wordcloud.to_file(path.join(pic_path+"wordcloud.jpg"))
plt.imshow(wordcloud) # imshow()の役割:画像を2次元座標軸に表示
plt.axis("off") # 座標軸を表示しない
plt.show() # 画像を表示
効果は以下の通りです:

もちろん、このようなコードはあまりにも醜いので、後で時間があれば可視化 GUI を使用して作成するようにします。
すべてのコードとサンプルファイルのダウンロードリンク:https://www.lanzous.com/i31rsdc