前言#
不管是暴力破解還是反爬蟲,代理池都是必不可少的一個條件
關於代理池的獲取,我們在上一篇文章:《多線程爬取西刺高匿代理並驗證可用性》已經介紹過了
我們就用這篇文章獲得的驗證過的代理來試一下刷訪問量
醜陋的代碼實現#
大部分代碼實現都是照搬上面說的這篇文章的
唯一不同的是學到一個庫叫做 fake_useragent,可以用它生成隨機的 User-Agent,簡單示例代碼如下:
from fake_useragent import UserAgent
ua = UserAgent() # 用於生成User-Agent
headers = {"User-Agent": ua.random} # 獲得一個隨機的User-Agent
print(headers)
需要指定瀏覽器的 User-Agent 可以參考這篇文章:https://blog.csdn.net/qq_29186489/article/details/78496747
全代碼:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@fucntion: 用代理ip池刷訪問量
@time: 2019-01-23
'''
import os
import requests
from fake_useragent import UserAgent
from multiprocessing import Pool
import timeit
url = "https://soapffz.com/" # 要刷取的網頁
ua = UserAgent() # 用於生成User-Agent
path = os.path.join(os.path.expanduser("~")+"\\")
http_proxy_path = os.path.join(
path+"Desktop"+"\\"+"http_proxy.txt") # 這是我自己的代理ip的位置
https_proxy_path = os.path.join(
path+"Desktop"+"\\"+"https_proxy.txt") # 根據自己位置不同自己修改
http_proxy = [] # 存儲http代理
https_proxy = [] # 存儲https代理
def brush_visits(proxies):
proxy_type = proxies.split(":")[0]
if proxy_type == 'http':
proxy = {'http': proxies}
else:
proxy = {'https': proxies}
headers = {"User-Agent": ua.random} # 獲得一個隨機的User-Agent
req = requests.get(url, headers=headers, proxies=proxy, timeout=10)
if req.status_code == 200:
print("此代理訪問成功:{}".format(proxies))
if __name__ == "__main__":
start_time = timeit.default_timer()
if not os.path.exists(http_proxy_path):
print("代理都沒準備好還想刷訪問量?滾吧您!")
os._exit(0)
with open(http_proxy_path, 'r') as f:
http_proxy = f.read().splitlines()
with open(https_proxy_path, 'r') as f:
https_proxy = f.read().splitlines()
pool1 = Pool()
pool2 = Pool()
for proxies in http_proxy:
pool1.apply_async(brush_visits, args=(proxies,))
for proxies in https_proxy:
pool2.apply_async(brush_visits, args=(proxies,))
pool1.close()
pool2.close()
pool1.join()
pool2.join()
end_time = timeit.default_timer()
print("代理池已經用完了,共用時耗時{}s".format(end_time-start_time))
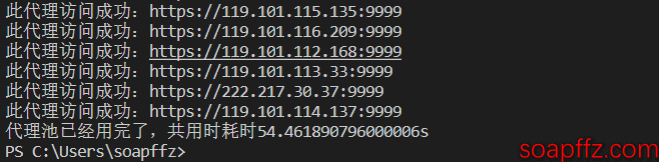
效果展示如下:
更新#
[2019-08-27 更新] 前面寫的是基於文件的讀取,現在看來有點沙雕,加上最近有用到這個的需求,更新下
前期準備只需要你安裝好Mongodb數據庫即可,可參考我之前寫過的文章《Win10 安裝 mongodb》
然後就可以直接運行此代碼,修改其中想要刷取的界面即可,全代碼如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@author: soapffz
@fucntion: 用代理ip池批量刷取網站訪問量(讀取本地mongodb數據庫中的代理集合)
@time: 2019-08-27
'''
from os import popen
from threading import Thread # 多線程
from pymongo import MongoClient
from requests import get
from lxml import etree # 解析站點
from re import split # re解析庫
from telnetlib import Telnet # telnet連接測試代理有效性
from fake_useragent import UserAgent
from multiprocessing import Pool
def brush_visits(url, proxy):
# 用單個代理訪問單個頁面
try:
ua = UserAgent() # 用於生成User-Agent
headers = {"User-Agent": ua.random} # 獲得一個隨機的User-Agent
req = get(url, headers=headers, proxies=proxy, timeout=0.3)
if req.status_code == 200:
print("此代理{}貢獻了一次訪問".format(proxy))
except Exception as e:
pass
class batch_brush_visits(object):
def __init__(self, url):
self.url = url
self.ua = UserAgent() # 用於生成User-Agent
self.run_time = 0 # 運行次數
self.conn_db()
self.get_proxies_l()
def conn_db(self):
# 連接數據庫
try:
# 連接mongodb,得到連接對象
self.client = MongoClient('mongodb://localhost:27017/').proxies
self.db = self.client.xici # 指定proxies數據庫,這個類都使用這個數據庫,沒有數據不會自動創建
self.refresh_proxies()
except Exception as e:
print("數據庫連接出錯")
exit(0)
def refresh_proxies(self):
if "xici" in self.client.list_collection_names():
# 每次初始化時刪除已有的集合
self.db.drop()
t = Thread(target=self.xici_nn_proxy_start)
t.start()
t.join()
def get_proxies_l(self):
# 讀取對應集合中ip和port信息
collection_dict_l = self.db.find(
{}, {"_id": 0, "ip": 1, "port": 1, "type": 1})
self.proxies_l = []
for item in collection_dict_l:
if item["type"] == 'http':
self.proxies_l.append(
{"http": "{}:{}".format(item['ip'], item['port'])})
else:
self.proxies_l.append(
{"https": "{}:{}".format(item['ip'], item['port'])})
if len(self.proxies_l) == 0:
print("沒有獲取到代理,刷個屁...")
exit(0)
else:
self.brush_visits_start()
def xici_nn_proxy_start(self):
xici_t_cw_l = [] # 爬取線程列表
self.xici_crawled_proxies_l = [] # 每次爬取之前先清空
for i in range(1, 11): # 爬取10頁代理
t = Thread(target=self.xici_nn_proxy, args=(i,))
xici_t_cw_l.append(t) # 添加線程到線程列表
t.start()
for t in xici_t_cw_l: # 等待所有線程完成退出主線程
t.join()
# 插入數據庫
self.db_insert(self.xici_crawled_proxies_l)
def xici_nn_proxy(self, page):
# 西刺代理爬取函數
url = "https://www.xicidaili.com/nn/{}".format(page)
# 這裡不加user-agent會返回狀態碼503
req = get(url, headers={"User-Agent": self.ua.random})
if req.status_code == 200:
# 狀態碼是其他的值表示ip被封
content = req.content.decode("utf-8")
tree = etree.HTML(content)
# 用xpath獲得總的ip_list
tr_nodes = tree.xpath('.//table[@id="ip_list"]/tr')[1:]
for tr_node in tr_nodes:
td_nodes = tr_node.xpath('./td') # 用xpath獲得單個ip的標籤
speed = int(split(r":|%", td_nodes[6].xpath(
'./div/div/@style')[0])[1]) # 獲得速度的值
conn_time = int(split(r":|%", td_nodes[7].xpath(
'./div/div/@style')[0])[1]) # 獲得連接時間的值
if(speed <= 85 | conn_time <= 85): # 如果速度和連接時間都不理想,就跳過這個代理
continue
ip = td_nodes[1].text
port = td_nodes[2].text
ip_type = td_nodes[5].text.lower()
self.get_usable_proxy(ip, port, ip_type, "xici")
def get_usable_proxy(self, ip, port, ip_type, proxy_name):
proxies_l = {"ip": ip, "port": port, "type": ip_type}
if proxies_l not in self.xici_crawled_proxies_l:
try:
# 用telnet連接一下,能連通說明代理可用
Telnet(ip, port, timeout=0.3)
except:
pass
else:
self.xici_crawled_proxies_l.append(proxies_l)
def db_insert(self, proxies_list):
if proxies_list:
# 傳入的列表為空則退出
self.db.insert_many(proxies_list) # 插入元素為字典的列表
print(
"數據已插入完畢!\n此次共插入{}個代理到xici集合中!".format(len(proxies_list)))
else:
print(
"爬到的代理列表為空!\n如果你很快看到這條消息\n估計ip已被封\n請掛vpn!\n否則最新代理都已在數據庫中了\n不用再爬了!")
def brush_visits_start(self):
# 用獲得的代理刷取頁面
try:
self.run_time += 1
pool = Pool()
for proxy in self.proxies_l:
pool.apply_async(brush_visits(self.url, proxy))
pool.close()
pool.join()
if self.run_time == 100:
print("已刷取一百次,重新獲取代理")
self.refresh_proxies()
print("已刷取完一遍")
self.brush_visits_start()
except Exception as e:
print("程序運行報錯退出:{}".format(e))
exit(0)
if __name__ == "__main__":
url = "https://soapffz.com/3.html" # 在這裡填寫需要刷取的url
batch_brush_visits(url)
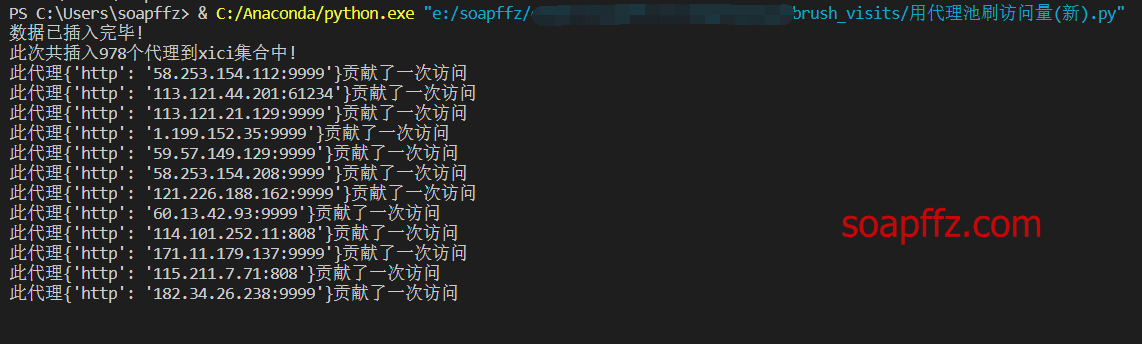
效果如下:
另外,文中的代碼設計的是為一個url刷取,如果你需要同時刷取多個url
需要使用到笛卡爾乘積,使用例子如下:
from itertools import product
urls_l = ["https://soapffz.com/279.html",
"https://soapffz.com/timeline.html", "https://soapffz.com/372.html"]
proxies_l = ["120.120.120.121", "1.1.1.1", "231.220.15.2"]
paramlist = list(product(urls_l, proxies_l))
for i in range(len(paramlist)):
print(paramlist[i])
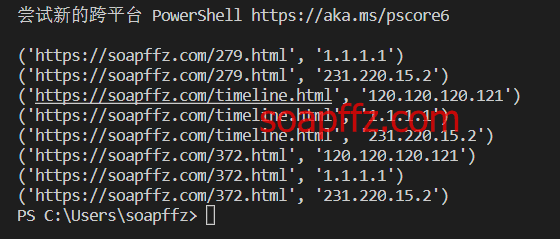
效果如下:
所以,你需要如下改動:
- 導入這個庫:
from itertools import product
main函數中的 url 改為列表
if __name__ == "__main__":
urls_l = ["https://soapffz.com/3.html"] # 在這裡填寫需要刷取的urls列表
batch_brush_visits(urls_l)
- 刷取目標改為笛卡爾乘積
batch_brush_visits類中的brush_visits_start部分代碼改動如下:
pool = Pool()
for proxy in self.proxies_l:
pool.apply_async(brush_visits(self.url, proxy))
pool.close()
pool.join()
改為
paramlist = list(product(self.urls_l, self.proxies_l))
pool = Pool()
for i in range(len(paramlist)):
pool.apply_async(brush_visits(paramlist[i]))
pool.close()
pool.join()
- 改動訪問函數
brush_visits函數改動如下,由
def brush_visits(url, proxy):
# 用單個代理訪問單個頁面
try:
ua = UserAgent() # 用於生成User-Agent
headers = {"User-Agent": ua.random} # 獲得一個隨機的User-Agent
req = get(url, headers=headers, proxies=proxy, timeout=0.3)
if req.status_code == 200:
print("此代理{}貢獻了一次訪問".format(proxy))
except Exception as e:
pass
改為:
def brush_visits(paramlist):
# 用單個代理訪問單個頁面
try:
url = paramlist[0]
proxy = paramlist[1]
ua = UserAgent() # 用於生成User-Agent
headers = {"User-Agent": ua.random} # 獲得一個隨機的User-Agent
req = get(url, headers=headers, proxies=proxy, timeout=0.3)
if req.status_code == 200:
print("此代理:{}貢獻一次訪問".format(proxy))
except Exception as e:
pass
就差不多了,可以實現每個代理訪問一次每一個url的效果
本文完。