前言#
为啥要用代理? 不管是爆破还是爬虫,经常都会遇见 ip 被封掉的情况,此时,自建一个可靠的代理池就显得很有必要了
代理有哪些分类 以代理的匿名度来分,可以分为透明代理、匿名代理和高度匿名代理
- 使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实 IP。
- 使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实 IP。
- 使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实 IP。
此篇文章就是爬取国内比较出名的西刺代理 (还有一个快代理也比较出名,爬取步骤和这个差不多) 的高匿代理并且验证可用性
思路#
获取信息#
首先,我们需要用 requests 库把网页爬下来,然后查看我们需要的信息在哪个标签页里
可以看到每一个代理的所有信息都包含在一个 tr 标签中,而每一个信息又都是放在一个 td 标签中的:
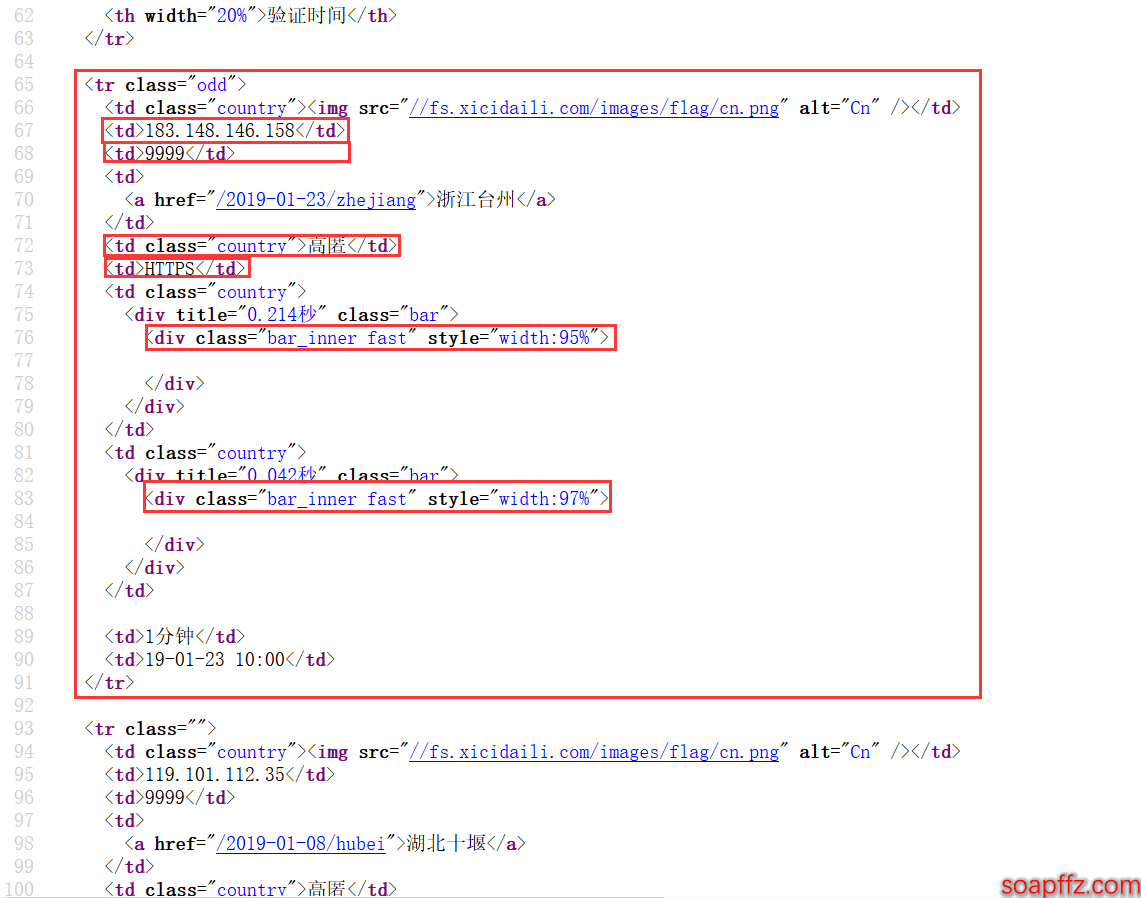
那么我们就可以使用 lxml 库来解析,用 xpath 来寻找标签,简单示例代码如下:
import requests
from lxml import etree
url = 'https://www.xicidaili.com/nn/1' # 需要爬取的url
req = requests.get(url) # 用requests请求
content = req.content.decode("utf-8") # 将内容解码
tree = etree.HTML(content) # 解析html文件
tr_nodes = tree.xpath('.//table[@id="ip_list"]/tr')[1:] # 使用xpath解析所需要的标签
用 xpath 获得指定标签页的内容可以参考这篇文章:https://www.cnblogs.com/lei0213/p/7506130.html
在获得每个端口 ip、端口、类型、速度、连接时间等信息之后,我们可以进行筛选:
- 将 http、https 类型的代理 ip 分类
- 将速度及连接时间不理想的 ip 过滤掉
验证有效性#
之后,我们可以将代理 ip 拿去验证
验证方法的话,网上大部分是再将代理 ip 加载请求头里面拿去请求某个网站,比如百度
如果返回状态码是 200 的话,则此代理 ip 有效
但是这样太过于依赖网络并且效率也不高,看到一篇文章是用每个 ip 用 telnet 去连接一下,如果能连接上,则是有效的
这部分主要的一个参数就是超时时间,也就是等待时间,建议设置为 10 秒
用 telnet 验证代理 ip 有效性的简单示例如下:
import telnetlib
def verifyProxy(ip, port):
try:
telnetlib.Telnet(ip, port, timeout=5) # 用 telnet 连接一下,能连通说明代理可用
except:
pass
else:
print("此代理已验证可用:{}".format(proxies))
if **name** == "**main**":
verifyProxy("113.13.177.80", "9999")
用多线程优化#
在获取信息,验证有效性都可行之后,发现效率太低了,主要耗费时间的地方有这些:
- 请求多页耗费时间
- 验证代理需要有一个超时等待时间,后面的队伍都需要等待
那么我们可以使用 multiprocessing 库中的 Pool 线程池配合 apply_async () 这个方法使用
这个线程池可以配合 apply () 方法使用,但是 apply () 是阻塞的。
首先主进程开始运行,碰到子进程,操作系统切换到子进程,等待子进程运行结束后,在切换到另外一个子进程,直到所有子进程运行完毕。然后在切换到主进程,运行剩余的部分。这样跟单进程串行执行没什么区别。
apply_async 是异步非阻塞的。
即不用等待当前进程执行完毕,随时根据系统调度来进行进程切换。首先主进程开始运行,碰到子进程后,主进程仍可以先运行,等到操作系统进行进程切换的时候,在交给子进程运行。可以做到不等待子进程执行完毕,主进程就已经执行完毕,并退出程序。
由于我们是获取到代理、验证有效性就行,不要求顺序,不需要像爬取小说那样爬取之后需要按照章节顺序存入文件
所以我们这里使用 apply_async 是最合适的。
multiprocessing 库中的 Pool 线程池配合 apply_async () 这个方法的简单示例代码如下:
from multiprocessing import Pool
def example(proxies):
if type(proxies) == 'http':
with open("1.txt", 'a') as f:
f.write(proxies+"\n")
else:
with open("2.txt", 'a') as f:
f.write(proxies+"\n")
if **name** == "**main**":
proxy = []
with open("tmp.txt", 'r') as f:
proxy = f.read().splitlines()
pool = Pool() # 新建一个线程池
for line in proxy:
pool.apply_async(target=example, args=(line,)) # target 这个参数名可以省略,建议在最后一个参数后面加上一个,
pool.close() # 创建进程池之后必须关闭
pool.join() # 加入阻塞队列,则要上面的代码执行完毕之后,才会执行后面的代码
具体代码实现#
关键地方都已做了注释:
#!/usr/bin/python
# -_- coding: utf-8 -_-
'''
@author: soapffz
@fucntion: 多线程爬取西刺高匿代理并验证可用性
@time: 2019-01-21
'''
import requests
from lxml import etree
import re
import telnetlib
import threading
from multiprocessing import Pool
import os
import timeit
path = os.path.join(os.path.expanduser("~")+"\\") # 爬下来未验证的的代理先放在当前用户根目录下
http_tmp_path = os.path.join(path+"http_tmp.txt")
https_tmp_path = os.path.join(path+"https_tmp.txt")
# 验证过的代理就放在当前用户桌面
http_proxy_path = os.path.join(path+"Desktop"+"\\"+"http_proxy.txt")
https_proxy_path = os.path.join(path+"Desktop"+"\\"+"https_proxy.txt")
http_proxy = []
https_proxy = []
def get_nn_proxy(page_num):
url = "https://www.xicidaili.com/nn/{}".format(page_num)
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'} # 本来还测试使用随机 User-Agent 头,后来发现没用,西刺封的是 ip
req = requests.get(url, headers=headers)
print("正在爬取第{}页的内容...".format(page_num))
content = req.content.decode("utf-8")
tree = etree.HTML(content) # 用 xpath 获得总的 ip_list
tr_nodes = tree.xpath('.//table[@id="ip_list"]/tr')[1:]
for tr_node in tr_nodes:
td_nodes = tr_node.xpath('./td') # 用 xpath 获得单个 ip 的标签
speed = int(
re.split(r":|%", td_nodes[6].xpath('./div/div/@style')[0])[1]) # 获得速度的值
conn_time = int(
re.split(r":|%", td_nodes[7].xpath('./div/div/@style')[0])[1]) # 获得连接时间的值
if(speed <= 95 | conn_time <= 95): # 如果速度和连接时间都不理想,就跳过这个代理
continue
ip = td_nodes[1].text
port = td_nodes[2].text
proxy_type = td_nodes[4].text
ip_type = td_nodes[5].text.lower()
proxy = "{}:{}".format(ip, port)
if ip_type == 'http':
with open(http_tmp_path, 'a') as f:
f.write("http://{}".format(proxy)+"\n") # 获得爬下来的 http 代理并存在临时文件中
else:
with open(https_tmp_path, 'a') as f: # 获得爬下来的 https 代理并存在临时文件中
f.write("https://{}".format(proxy)+"\n")
def verifyProxy(proxies):
ree = re.split(r'//|:', proxies)
ip_type = ree[0]
ip = ree[2]
port = ree[3]
try:
telnetlib.Telnet(ip, port, timeout=5) # 用 telnet 连接一下,能连通说明代理可用
except:
pass
else:
print("此代理已验证可用:{}".format(proxies))
if ip_type == 'http':
with open(http_proxy_path, 'a') as f:
f.write(proxies+"\n")
else:
with open(https_proxy_path, 'a') as f:
f.write(proxies+"\n")
def clear_cache(path):
if os.path.exists(path):
os.remove(path)
if **name** == "**main**":
start_time = timeit.default_timer()
clear_cache(http_tmp_path)
clear_cache(https_tmp_path)
clear_cache(http_proxy_path)
clear_cache(https_proxy_path)
pool = Pool()
for i in range(1, 11): # 这里爬取的是 1 到 10 页的高匿代理,自行根据需要修改参数
pool.apply_async(get_nn_proxy, args=(i,))
pool.close()
pool.join()
if not os.path.exists(http_tmp_path): # 如果 ip 被 ban 掉,则获取到的每一页代理都是空列表,不会生成文件
print("你的 ip 已经被西刺 ban 掉了,请使用 ipconfig /release 之后使用 ipconfig /renew 换 ip 或者挂 vpn!")
os.\_exit(0)
with open(http_tmp_path, 'r') as f:
http_proxy = f.read().splitlines()
Unhttp_proxy_num = len(http_proxy)
with open(https_tmp_path, 'r') as f:
https_proxy = f.read().splitlines()
Unhttps_proxy_num = len(https_proxy)
pool2 = Pool()
pool3 = Pool()
for proxies in http_proxy:
pool2.apply_async(verifyProxy, args=(proxies,))
for proxies in https_proxy:
pool3.apply_async(verifyProxy, args=(proxies,))
pool2.close()
pool3.close()
pool2.join()
pool3.join()
http_proxy.clear()
https_proxy.clear()
with open(http_proxy_path, 'r') as f:
http_proxy = f.read().splitlines()
http_proxy_num = len(http_proxy)
with open(https_proxy_path, 'r') as f:
https_proxy = f.read().splitlines()
https_proxy_num = len(https_proxy)
print(http_proxy)
print(https_proxy)
print("已存储在 http_proxy 和 https_proxy 这两个列表中并已将 txt 保存在桌面")
end_time = timeit.default_timer()
print("共爬取{}个 http 代理,可用{}个,爬取{}个 https 代理,可用{}个,总耗时{}s".format(Unhttp_proxy_num,
http_proxy_num, Unhttps_proxy_num, https_proxy_num, end_time-start_time))
提示:由于代理的时效性,不建议长期存储,建议 “即用即爬”,另外请勿重复使用,短时间内使用两三次就会封掉 ip,如果 ip 被封的话挂 vpn 即可
效果展示#
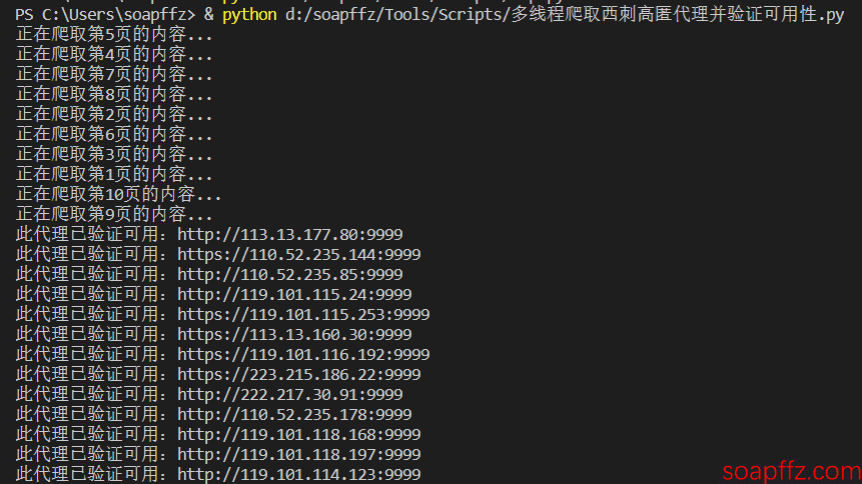
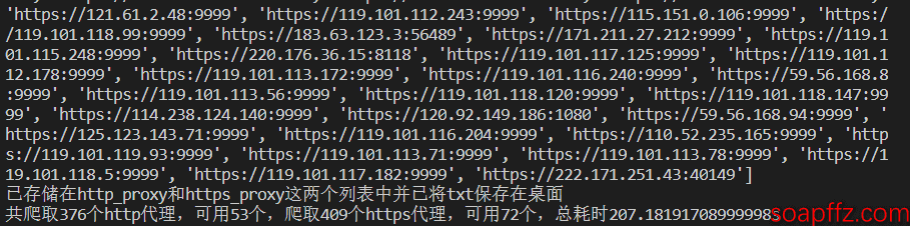
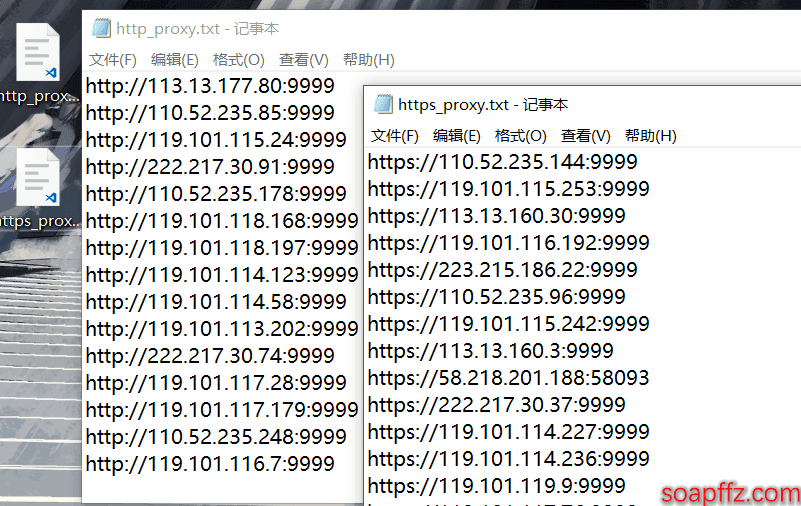
可以看到免费的高匿 ip 的有效个数还是很少的,376 个 http 代理只有 53 个可用,409 和 https 代理只有 72 个可用。