Introduction#
Why use proxies? Whether it's for brute force attacks or web crawling, it's common to encounter situations where the IP gets banned. At this point, building a reliable proxy pool becomes necessary.
What are the classifications of proxies? Based on the level of anonymity, proxies can be classified into transparent proxies, anonymous proxies, and highly anonymous proxies.
- Using a transparent proxy, the target server can know that you are using a proxy and also your real IP.
- Using an anonymous proxy, the target server can know that you are using a proxy but does not know your real IP.
- Using a highly anonymous proxy, the target server does not know that you are using a proxy and does not know your real IP.
This article focuses on crawling the well-known Xici proxy (another well-known one is Kuai Proxy, with similar crawling steps) for high-anonymity proxies and validating their availability.
Approach#
Information Gathering#
First, we need to use the requests library to crawl the webpage and then check which tag contains the information we need.
We can see that all the information for each proxy is contained within a tr tag, and each piece of information is placed within a td tag:
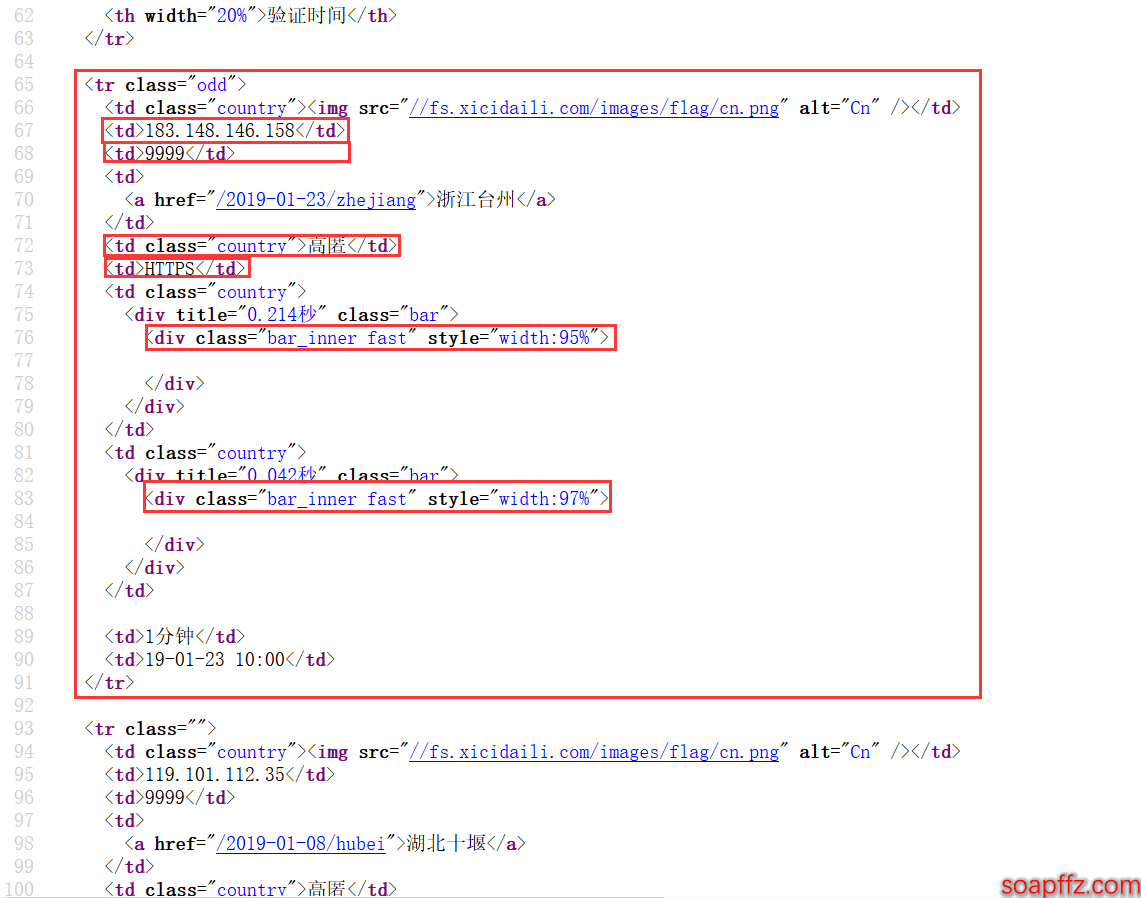
We can then use the lxml library to parse it and use xpath to find the tags. A simple example code is as follows:
import requests
from lxml import etree
url = 'https://www.xicidaili.com/nn/1' # URL to crawl
req = requests.get(url) # Request using requests
content = req.content.decode("utf-8") # Decode the content
tree = etree.HTML(content) # Parse the HTML file
tr_nodes = tree.xpath('.//table[@id="ip_list"]/tr')[1:] # Use xpath to parse the required tags
For obtaining the content of specified tags using xpath, you can refer to this article: https://www.cnblogs.com/lei0213/p/7506130.html
After obtaining information such as IP, port, type, speed, connection time, etc., we can filter them:
- Classify the proxy IPs into http and https types
- Filter out IPs with unsatisfactory speed and connection time
Validating Availability#
Next, we can validate the proxy IPs.
Most methods found online involve loading the proxy IP into the request headers to request a certain website, such as Baidu.
If the returned status code is 200, then this proxy IP is valid.
However, this approach is too dependent on the network and not very efficient. I saw an article suggesting using telnet to connect to each IP; if it can connect, then it is valid.
A key parameter here is the timeout, which is the waiting time, and it is recommended to set it to 10 seconds.
A simple example of using telnet to validate the availability of proxy IPs is as follows:
import telnetlib
def verifyProxy(ip, port):
try:
telnetlib.Telnet(ip, port, timeout=5) # Connect using telnet; if it connects, the proxy is available
except:
pass
else:
print("This proxy has been validated as available: {}".format(proxies))
if __name__ == "__main__":
verifyProxy("113.13.177.80", "9999")
Optimizing with Multithreading#
After obtaining information and validating availability, we find that the efficiency is too low, mainly due to the following time-consuming factors:
- Requesting multiple pages takes time
- Validating proxies requires a timeout waiting period, causing subsequent requests to wait
We can use the Pool thread pool from the multiprocessing library in combination with the apply_async() method.
This thread pool can be used with the apply() method, but apply() is blocking.
First, the main process starts running, encounters a child process, the operating system switches to the child process, waits for the child process to finish running, and then switches to another child process until all child processes are completed. Then it switches back to the main process to run the remaining part. This is no different from executing in a single process serially.
apply_async is asynchronous and non-blocking.
This means that you do not have to wait for the current process to finish executing; you can switch processes at any time according to system scheduling. First, the main process starts running, and when it encounters a child process, the main process can continue to run. When the operating system performs a process switch, it hands over control to the child process. This allows the main process to finish executing and exit the program without waiting for the child process to complete.
Since we only need to obtain proxies and validate their availability without requiring order (unlike crawling novels that need to be stored in chapter order), using apply_async is the most suitable.
A simple example code using the Pool thread pool from the multiprocessing library with apply_async() is as follows:
from multiprocessing import Pool
def example(proxies):
if type(proxies) == 'http':
with open("1.txt", 'a') as f:
f.write(proxies+"\n")
else:
with open("2.txt", 'a') as f:
f.write(proxies+"\n")
if __name__ == "__main__":
proxy = []
with open("tmp.txt", 'r') as f:
proxy = f.read().splitlines()
pool = Pool() # Create a new thread pool
for line in proxy:
pool.apply_async(target=example, args=(line,)) # The target parameter name can be omitted; it's recommended to add a comma after the last parameter
pool.close() # Must close the process pool after creation
pool.join() # Join the blocking queue, so the subsequent code will only execute after the above code is completed
Specific Code Implementation#
Key parts have been commented:
#!/usr/bin/python
# -_- coding: utf-8 -_-
'''
@author: soapffz
@function: Multithreaded Crawling of Xici High-Anonymity Proxies and Validating Availability
@time: 2019-01-21
'''
import requests
from lxml import etree
import re
import telnetlib
import threading
from multiprocessing import Pool
import os
import timeit
path = os.path.join(os.path.expanduser("~")+"\\") # Store unverified proxies in the current user's root directory
http_tmp_path = os.path.join(path+"http_tmp.txt")
https_tmp_path = os.path.join(path+"https_tmp.txt")
# Verified proxies will be stored on the current user's desktop
http_proxy_path = os.path.join(path+"Desktop"+"\\"+"http_proxy.txt")
https_proxy_path = os.path.join(path+"Desktop"+"\\"+"https_proxy.txt")
http_proxy = []
https_proxy = []
def get_nn_proxy(page_num):
url = "https://www.xicidaili.com/nn/{}".format(page_num)
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'} # Initially tested using random User-Agent headers, but later found it ineffective; Xici bans IPs
req = requests.get(url, headers=headers)
print("Crawling content from page {}...".format(page_num))
content = req.content.decode("utf-8")
tree = etree.HTML(content) # Use xpath to obtain the total ip_list
tr_nodes = tree.xpath('.//table[@id="ip_list"]/tr')[1:]
for tr_node in tr_nodes:
td_nodes = tr_node.xpath('./td') # Use xpath to obtain the individual IP tags
speed = int(
re.split(r":|%", td_nodes[6].xpath('./div/div/@style')[0])[1]) # Obtain the speed value
conn_time = int(
re.split(r":|%", td_nodes[7].xpath('./div/div/@style')[0])[1]) # Obtain the connection time value
if(speed <= 95 | conn_time <= 95): # If speed and connection time are unsatisfactory, skip this proxy
continue
ip = td_nodes[1].text
port = td_nodes[2].text
proxy_type = td_nodes[4].text
ip_type = td_nodes[5].text.lower()
proxy = "{}:{}".format(ip, port)
if ip_type == 'http':
with open(http_tmp_path, 'a') as f:
f.write("http://{}".format(proxy)+"\n") # Store the crawled http proxy in a temporary file
else:
with open(https_tmp_path, 'a') as f: # Store the crawled https proxy in a temporary file
f.write("https://{}".format(proxy)+"\n")
def verifyProxy(proxies):
ree = re.split(r'//|:', proxies)
ip_type = ree[0]
ip = ree[2]
port = ree[3]
try:
telnetlib.Telnet(ip, port, timeout=5) # Connect using telnet; if it connects, the proxy is available
except:
pass
else:
print("This proxy has been validated as available: {}".format(proxies))
if ip_type == 'http':
with open(http_proxy_path, 'a') as f:
f.write(proxies+"\n")
else:
with open(https_proxy_path, 'a') as f:
f.write(proxies+"\n")
def clear_cache(path):
if os.path.exists(path):
os.remove(path)
if __name__ == "__main__":
start_time = timeit.default_timer()
clear_cache(http_tmp_path)
clear_cache(https_tmp_path)
clear_cache(http_proxy_path)
clear_cache(https_proxy_path)
pool = Pool()
for i in range(1, 11): # Crawling high-anonymity proxies from pages 1 to 10; modify parameters as needed
pool.apply_async(get_nn_proxy, args=(i,))
pool.close()
pool.join()
if not os.path.exists(http_tmp_path): # If the IP is banned, the proxies obtained from each page will be an empty list, and no file will be generated
print("Your IP has been banned by Xici. Please use ipconfig /release followed by ipconfig /renew to change your IP or use a VPN!")
os._exit(0)
with open(http_tmp_path, 'r') as f:
http_proxy = f.read().splitlines()
Unhttp_proxy_num = len(http_proxy)
with open(https_tmp_path, 'r') as f:
https_proxy = f.read().splitlines()
Unhttps_proxy_num = len(https_proxy)
pool2 = Pool()
pool3 = Pool()
for proxies in http_proxy:
pool2.apply_async(verifyProxy, args=(proxies,))
for proxies in https_proxy:
pool3.apply_async(verifyProxy, args=(proxies,))
pool2.close()
pool3.close()
pool2.join()
pool3.join()
http_proxy.clear()
https_proxy.clear()
with open(http_proxy_path, 'r') as f:
http_proxy = f.read().splitlines()
http_proxy_num = len(http_proxy)
with open(https_proxy_path, 'r') as f:
https_proxy = f.read().splitlines()
https_proxy_num = len(https_proxy)
print(http_proxy)
print(https_proxy)
print("Stored in the http_proxy and https_proxy lists and saved txt files on the desktop")
end_time = timeit.default_timer()
print("Crawled {} http proxies, {} available, crawled {} https proxies, {} available, total time {}s".format(Unhttp_proxy_num,
http_proxy_num, Unhttps_proxy_num, https_proxy_num, end_time-start_time))
Note: Due to the time sensitivity of proxies, long-term storage is not recommended. It is advised to "crawl as needed." Additionally, do not reuse proxies; using them two or three times in a short period will lead to IP bans. If your IP gets banned, just use a VPN.
Effect Display#
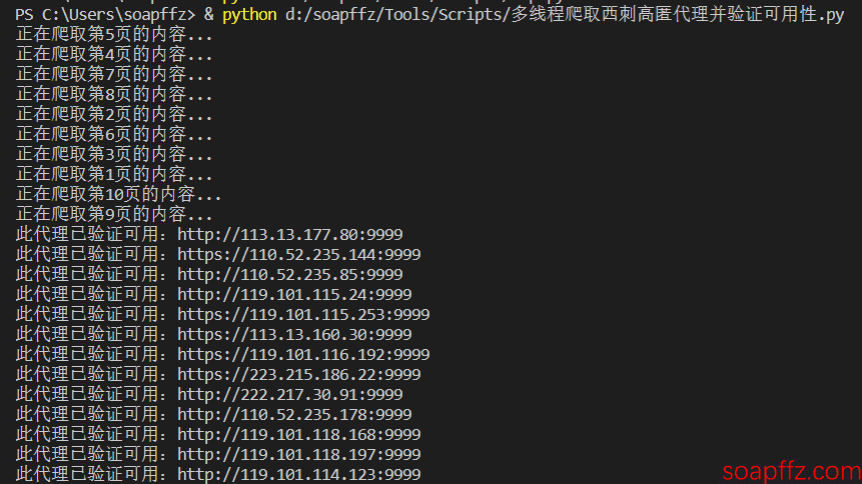
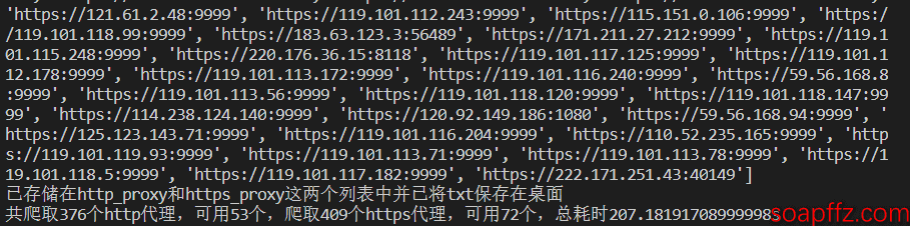
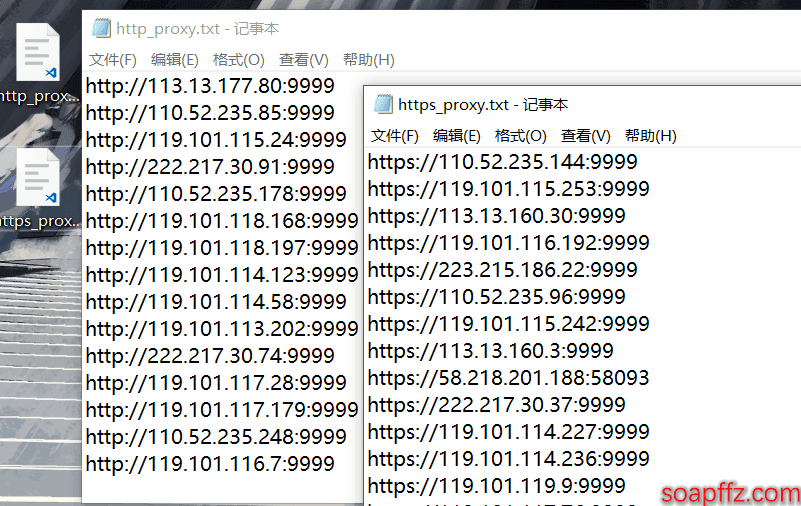
It can be seen that the number of valid free high-anonymity IPs is still quite small; out of 376 HTTP proxies, only 53 are available, and out of 409 HTTPS proxies, only 72 are available.